Update layer1-port-openscienceframework and same for zenodo
This commit is contained in:
parent
9fa2c2faab
commit
0dca8fc4f0
458 changed files with 0 additions and 35168 deletions
|
|
@ -1,23 +0,0 @@
|
|||
# Patterns to ignore when building packages.
|
||||
# This supports shell glob matching, relative path matching, and
|
||||
# negation (prefixed with !). Only one pattern per line.
|
||||
.DS_Store
|
||||
# Common VCS dirs
|
||||
.git/
|
||||
.gitignore
|
||||
.bzr/
|
||||
.bzrignore
|
||||
.hg/
|
||||
.hgignore
|
||||
.svn/
|
||||
# Common backup files
|
||||
*.swp
|
||||
*.bak
|
||||
*.tmp
|
||||
*.orig
|
||||
*~
|
||||
# Various IDEs
|
||||
.project
|
||||
.idea/
|
||||
*.tmproj
|
||||
.vscode/
|
||||
|
|
@ -1,8 +0,0 @@
|
|||
apiVersion: v2
|
||||
name: common
|
||||
description: A Helm chart for Kubernetes
|
||||
type: library
|
||||
version: 0.1.2
|
||||
appVersion: "1.16.0"
|
||||
sources:
|
||||
- https://github.com/Sciebo-RDS/Sciebo-RDS
|
||||
|
|
@ -1,65 +0,0 @@
|
|||
|
||||
{{/*
|
||||
Return the proper image name
|
||||
{{ include "common.image" ( dict "imageRoot" .Values.path.to.the.image "global" $) }}
|
||||
*/}}
|
||||
{{- define "common.image" -}}
|
||||
{{- $registryName := .imageRoot.registry -}}
|
||||
{{- $repositoryName := .imageRoot.repository -}}
|
||||
{{- if .repository -}}
|
||||
{{- $repositoryName = .repository -}}
|
||||
{{- end -}}
|
||||
{{- $tag := .imageRoot.tag | toString -}}
|
||||
{{- if .global }}
|
||||
{{- if .global.image }}
|
||||
{{- if .global.image.registry }}
|
||||
{{- $registryName = .global.image.registry -}}
|
||||
{{- end -}}
|
||||
{{- if .global.image.tag -}}
|
||||
{{- $tag = .global.image.tag | toString -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
{{- if $registryName }}
|
||||
{{- printf "%s/%s:%s" $registryName $repositoryName $tag -}}
|
||||
{{- else -}}
|
||||
{{- printf "%s:%s" $repositoryName $tag -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
|
||||
{{- define "common.ingressAnnotations" -}}
|
||||
{{- $annotations := dict -}}
|
||||
{{- with .Values.ingress.annotations }}
|
||||
{{- $annotations = . -}}
|
||||
{{- end -}}
|
||||
{{- if .Values.global }}
|
||||
{{- if .Values.global.ingress }}
|
||||
{{- if .Values.global.ingress.annotations }}
|
||||
{{- $annotations = mustMergeOverwrite .Values.global.ingress.annotations $annotations -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
{{- toYaml $annotations -}}
|
||||
{{- end -}}
|
||||
|
||||
|
||||
{{- define "common.tlsSecretName" -}}
|
||||
{{- $secretName := "" -}}
|
||||
{{- if .Values.ingress }}
|
||||
{{- if .Values.ingress.tls }}
|
||||
{{- if .Values.ingress.tls.secretName }}
|
||||
{{- $secretName = .Values.ingress.tls.secretName -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
{{- if .Values.global }}
|
||||
{{- if .Values.global.ingress }}
|
||||
{{- if .Values.global.ingress.tls }}
|
||||
{{- if .Values.global.ingress.tls.secretName }}
|
||||
{{- $secretName = .Values.global.ingress.tls.secretName -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
{{- printf "%s" $secretName -}}
|
||||
{{- end -}}
|
||||
|
|
@ -1,21 +0,0 @@
|
|||
# Patterns to ignore when building packages.
|
||||
# This supports shell glob matching, relative path matching, and
|
||||
# negation (prefixed with !). Only one pattern per line.
|
||||
.DS_Store
|
||||
# Common VCS dirs
|
||||
.git/
|
||||
.gitignore
|
||||
.bzr/
|
||||
.bzrignore
|
||||
.hg/
|
||||
.hgignore
|
||||
.svn/
|
||||
# Common backup files
|
||||
*.swp
|
||||
*.bak
|
||||
*.tmp
|
||||
*~
|
||||
# Various IDEs
|
||||
.project
|
||||
.idea/
|
||||
*.tmproj
|
||||
|
|
@ -1,23 +0,0 @@
|
|||
apiVersion: v1
|
||||
appVersion: 1.18.0
|
||||
description: A Jaeger Helm chart for Kubernetes
|
||||
home: https://jaegertracing.io
|
||||
icon: https://camo.githubusercontent.com/afa87494e0753b4b1f5719a2f35aa5263859dffb/687474703a2f2f6a61656765722e72656164746865646f63732e696f2f656e2f6c61746573742f696d616765732f6a61656765722d766563746f722e737667
|
||||
keywords:
|
||||
- jaeger
|
||||
- opentracing
|
||||
- tracing
|
||||
- instrumentation
|
||||
maintainers:
|
||||
- email: david.vonthenen@dell.com
|
||||
name: dvonthenen
|
||||
- email: michael.lorant@fairfaxmedia.com.au
|
||||
name: mikelorant
|
||||
- email: naseem@transit.app
|
||||
name: naseemkullah
|
||||
- email: pavel.nikolov@fairfaxmedia.com.au
|
||||
name: pavelnikolov
|
||||
name: jaeger
|
||||
sources:
|
||||
- https://hub.docker.com/u/jaegertracing/
|
||||
version: 0.34.1
|
||||
|
|
@ -1,10 +0,0 @@
|
|||
approvers:
|
||||
- dvonthenen
|
||||
- mikelorant
|
||||
- naseemkullah
|
||||
- pavelnikolov
|
||||
reviewers:
|
||||
- dvonthenen
|
||||
- mikelorant
|
||||
- naseemkullah
|
||||
- pavelnikolov
|
||||
|
|
@ -1,380 +0,0 @@
|
|||
# Jaeger
|
||||
|
||||
[Jaeger](https://www.jaegertracing.io/) is a distributed tracing system.
|
||||
|
||||
## Introduction
|
||||
|
||||
This chart adds all components required to run Jaeger as described in the [jaeger-kubernetes](https://github.com/jaegertracing/jaeger-kubernetes) GitHub page for a production-like deployment. The chart default will deploy a new Cassandra cluster (using the [cassandra chart](https://github.com/kubernetes/charts/tree/master/incubator/cassandra)), but also supports using an existing Cassandra cluster, deploying a new ElasticSearch cluster (using the [elasticsearch chart](https://github.com/elastic/helm-charts/tree/master/elasticsearch)), or connecting to an existing ElasticSearch cluster. Once the storage backend is available, the chart will deploy jaeger-agent as a DaemonSet and deploy the jaeger-collector and jaeger-query components as Deployments.
|
||||
|
||||
## Installing the Chart
|
||||
|
||||
Add the Jaeger Tracing Helm repository:
|
||||
|
||||
```bash
|
||||
helm repo add jaegertracing https://jaegertracing.github.io/helm-charts
|
||||
```
|
||||
|
||||
To install the chart with the release name `jaeger`, run the following command:
|
||||
|
||||
```bash
|
||||
helm install jaeger jaegertracing/jaeger
|
||||
```
|
||||
|
||||
By default, the chart deploys the following:
|
||||
|
||||
- Jaeger Agent DaemonSet
|
||||
- Jaeger Collector Deployment
|
||||
- Jaeger Query (UI) Deployment
|
||||
- Cassandra StatefulSet
|
||||
|
||||
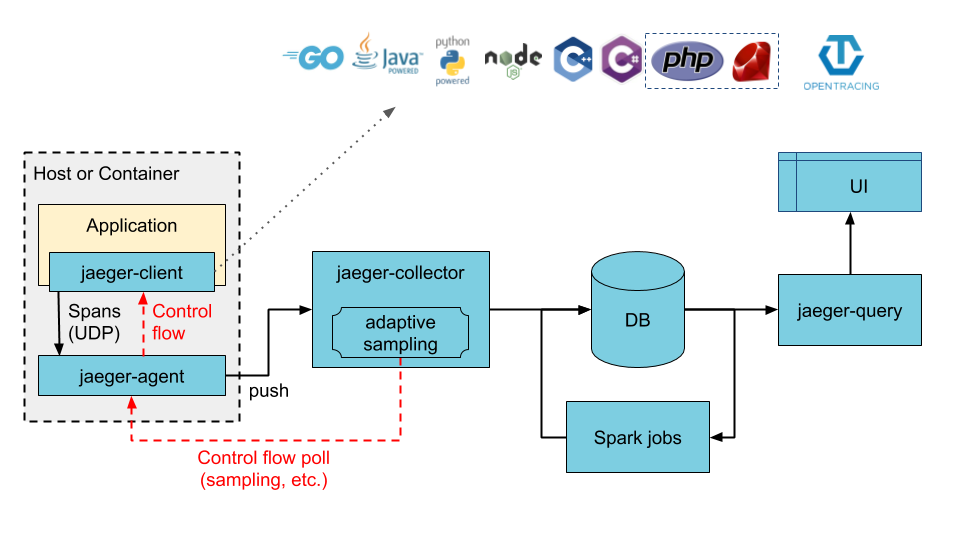
|
||||
|
||||
IMPORTANT NOTE: For testing purposes, the footprint for Cassandra can be reduced significantly in the event resources become constrained (such as running on your local laptop or in a Vagrant environment). You can override the resources required run running this command:
|
||||
|
||||
```bash
|
||||
helm install jaeger jaegertracing/jaeger \
|
||||
--set cassandra.config.max_heap_size=1024M \
|
||||
--set cassandra.config.heap_new_size=256M \
|
||||
--set cassandra.resources.requests.memory=2048Mi \
|
||||
--set cassandra.resources.requests.cpu=0.4 \
|
||||
--set cassandra.resources.limits.memory=2048Mi \
|
||||
--set cassandra.resources.limits.cpu=0.4
|
||||
```
|
||||
|
||||
## Installing the Chart using an Existing Cassandra Cluster
|
||||
|
||||
If you already have an existing running Cassandra cluster, you can configure the chart as follows to use it as your backing store (make sure you replace `<HOST>`, `<PORT>`, etc with your values):
|
||||
|
||||
```bash
|
||||
helm install jaeger jaegertracing/jaeger \
|
||||
--set provisionDataStore.cassandra=false \
|
||||
--set storage.cassandra.host=<HOST> \
|
||||
--set storage.cassandra.port=<PORT> \
|
||||
--set storage.cassandra.user=<USER> \
|
||||
--set storage.cassandra.password=<PASSWORD>
|
||||
```
|
||||
|
||||
## Installing the Chart using an Existing Cassandra Cluster with TLS
|
||||
|
||||
If you already have an existing running Cassandra cluster with TLS, you can configure the chart as follows to use it as your backing store:
|
||||
|
||||
Content of the `values.yaml` file:
|
||||
|
||||
```YAML
|
||||
storage:
|
||||
type: cassandra
|
||||
cassandra:
|
||||
host: <HOST>
|
||||
port: <PORT>
|
||||
user: <USER>
|
||||
password: <PASSWORD>
|
||||
tls:
|
||||
enabled: true
|
||||
secretName: cassandra-tls-secret
|
||||
|
||||
provisionDataStore:
|
||||
cassandra: false
|
||||
```
|
||||
|
||||
Content of the `jaeger-tls-cassandra-secret.yaml` file:
|
||||
|
||||
```YAML
|
||||
apiVersion: v1
|
||||
kind: Secret
|
||||
metadata:
|
||||
name: cassandra-tls-secret
|
||||
data:
|
||||
commonName: <SERVER NAME>
|
||||
ca-cert.pem: |
|
||||
-----BEGIN CERTIFICATE-----
|
||||
<CERT>
|
||||
-----END CERTIFICATE-----
|
||||
client-cert.pem: |
|
||||
-----BEGIN CERTIFICATE-----
|
||||
<CERT>
|
||||
-----END CERTIFICATE-----
|
||||
client-key.pem: |
|
||||
-----BEGIN RSA PRIVATE KEY-----
|
||||
-----END RSA PRIVATE KEY-----
|
||||
cqlshrc: |
|
||||
[ssl]
|
||||
certfile = ~/.cassandra/ca-cert.pem
|
||||
userkey = ~/.cassandra/client-key.pem
|
||||
usercert = ~/.cassandra/client-cert.pem
|
||||
|
||||
```
|
||||
|
||||
```bash
|
||||
kubectl apply -f jaeger-tls-cassandra-secret.yaml
|
||||
helm install jaeger jaegertracing/jaeger --values values.yaml
|
||||
```
|
||||
|
||||
## Installing the Chart using a New ElasticSearch Cluster
|
||||
|
||||
To install the chart with the release name `jaeger` using a new ElasticSearch cluster instead of Cassandra (default), run the following command:
|
||||
|
||||
```bash
|
||||
helm install jaeger jaegertracing/jaeger \
|
||||
--set provisionDataStore.cassandra=false \
|
||||
--set provisionDataStore.elasticsearch=true \
|
||||
--set storage.type=elasticsearch
|
||||
```
|
||||
|
||||
## Installing the Chart using an Existing Elasticsearch Cluster
|
||||
|
||||
A release can be configured as follows to use an existing ElasticSearch cluster as it as the storage backend:
|
||||
|
||||
```bash
|
||||
helm install jaeger jaegertracing/jaeger \
|
||||
--set provisionDataStore.cassandra=false \
|
||||
--set storage.type=elasticsearch \
|
||||
--set storage.elasticsearch.host=<HOST> \
|
||||
--set storage.elasticsearch.port=<PORT> \
|
||||
--set storage.elasticsearch.user=<USER> \
|
||||
--set storage.elasticsearch.password=<password>
|
||||
```
|
||||
|
||||
## Installing the Chart using an Existing ElasticSearch Cluster with TLS
|
||||
|
||||
If you already have an existing running ElasticSearch cluster with TLS, you can configure the chart as follows to use it as your backing store:
|
||||
|
||||
Content of the `jaeger-values.yaml` file:
|
||||
|
||||
```YAML
|
||||
storage:
|
||||
type: elasticsearch
|
||||
elasticsearch:
|
||||
host: <HOST>
|
||||
port: <PORT>
|
||||
scheme: https
|
||||
user: <USER>
|
||||
password: <PASSWORD>
|
||||
provisionDataStore:
|
||||
cassandra: false
|
||||
elasticsearch: false
|
||||
query:
|
||||
cmdlineParams:
|
||||
es.tls.ca: "/tls/es.pem"
|
||||
extraConfigmapMounts:
|
||||
- name: jaeger-tls
|
||||
mountPath: /tls
|
||||
subPath: ""
|
||||
configMap: jaeger-tls
|
||||
readOnly: true
|
||||
collector:
|
||||
cmdlineParams:
|
||||
es.tls.ca: "/tls/es.pem"
|
||||
extraConfigmapMounts:
|
||||
- name: jaeger-tls
|
||||
mountPath: /tls
|
||||
subPath: ""
|
||||
configMap: jaeger-tls
|
||||
readOnly: true
|
||||
spark:
|
||||
enabled: true
|
||||
cmdlineParams:
|
||||
java.opts: "-Djavax.net.ssl.trustStore=/tls/trust.store -Djavax.net.ssl.trustStorePassword=changeit"
|
||||
extraConfigmapMounts:
|
||||
- name: jaeger-tls
|
||||
mountPath: /tls
|
||||
subPath: ""
|
||||
configMap: jaeger-tls
|
||||
readOnly: true
|
||||
|
||||
```
|
||||
|
||||
Generate configmap jaeger-tls:
|
||||
|
||||
```bash
|
||||
keytool -import -trustcacerts -keystore trust.store -storepass changeit -alias es-root -file es.pem
|
||||
kubectl create configmap jaeger-tls --from-file=trust.store --from-file=es.pem
|
||||
```
|
||||
|
||||
```bash
|
||||
helm install jaeger jaegertracing/jaeger --values jaeger-values.yaml
|
||||
```
|
||||
|
||||
## Installing the Chart with Ingester enabled
|
||||
|
||||
The architecture illustrated below can be achieved by enabling the ingester component. When enabled, Cassandra or Elasticsearch (depending on the configured values) now becomes the ingester's storage backend, whereas Kafka becomes the storage backend of the collector service.
|
||||
|
||||
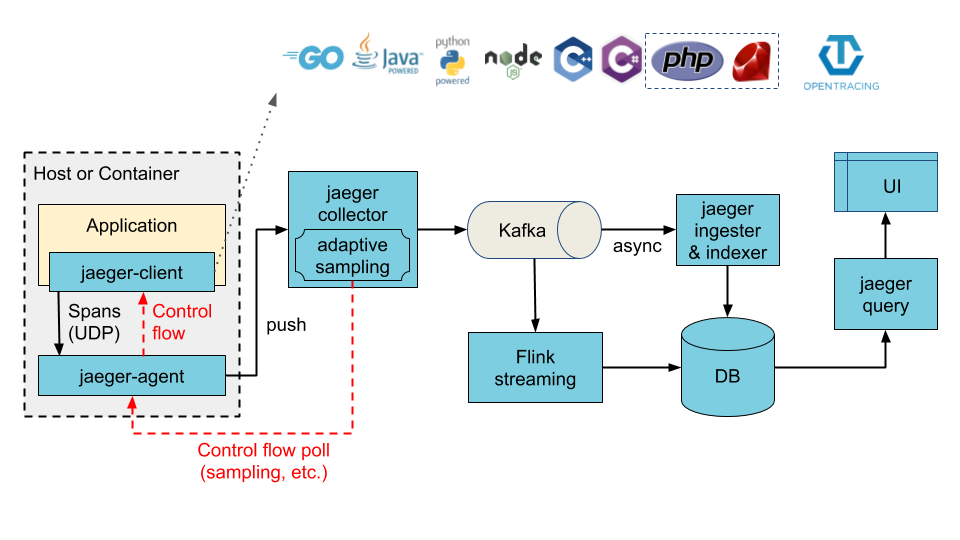
|
||||
|
||||
## Installing the Chart with Ingester enabled using a New Kafka Cluster
|
||||
|
||||
To provision a new Kafka cluster along with jaeger-ingester:
|
||||
|
||||
```bash
|
||||
helm install jaeger jaegertracing/jaeger \
|
||||
--set provisionDataStore.kafka=true \
|
||||
--set ingester.enabled=true
|
||||
```
|
||||
|
||||
## Installing the Chart with Ingester using an existing Kafka Cluster
|
||||
|
||||
You can use an exisiting Kafka cluster with jaeger too
|
||||
|
||||
```bash
|
||||
helm install jaeger jaegertracing/jaeger \
|
||||
--set ingester.enabled=true \
|
||||
--set storage.kafka.brokers={<BROKER1:PORT>,<BROKER2:PORT>} \
|
||||
--set storage.kafka.topic=<TOPIC>
|
||||
```
|
||||
|
||||
## Configuration
|
||||
|
||||
The following table lists the configurable parameters of the Jaeger chart and their default values.
|
||||
|
||||
| Parameter | Description | Default |
|
||||
|-----------|-------------|---------|
|
||||
| `<agent\|collector\|query\|ingester>.cmdlineParams` | Additional command line parameters | `nil` |
|
||||
| `<component>.extraEnv` | Additional environment variables | [] |
|
||||
| `<component>.nodeSelector` | Node selector | {} |
|
||||
| `<component>.tolerations` | Node tolerations | [] |
|
||||
| `<component>.affinity` | Affinity | {} |
|
||||
| `<component>.podAnnotations` | Pod annotations | `nil` |
|
||||
| `<component>.podSecurityContext` | Pod security context | {} |
|
||||
| `<component>.securityContext` | Container security context | {} |
|
||||
| `<component>.serviceAccount.create` | Create service account | `true` |
|
||||
| `<component>.serviceAccount.name` | The name of the ServiceAccount to use. If not set and create is true, a name is generated using the fullname template | `nil` |
|
||||
| `<component>.serviceMonitor.enabled` | Create serviceMonitor | `false` |
|
||||
| `<component>.serviceMonitor.additionalLabels` | Add additional labels to serviceMonitor | {} |
|
||||
| `agent.annotations` | Annotations for Agent | `nil` |
|
||||
| `agent.dnsPolicy` | Configure DNS policy for agents | `ClusterFirst` |
|
||||
| `agent.service.annotations` | Annotations for Agent SVC | `nil` |
|
||||
| `agent.service.binaryPort` | jaeger.thrift over binary thrift | `6832` |
|
||||
| `agent.service.compactPort` | jaeger.thrift over compact thrift| `6831` |
|
||||
| `agent.image` | Image for Jaeger Agent | `jaegertracing/jaeger-agent` |
|
||||
| `agent.imagePullSecrets` | Secret to pull the Image for Jaeger Agent | `[]` |
|
||||
| `agent.pullPolicy` | Agent image pullPolicy | `IfNotPresent` |
|
||||
| `agent.service.loadBalancerSourceRanges` | list of IP CIDRs allowed access to load balancer (if supported) | `[]` |
|
||||
| `agent.service.annotations` | Annotations for Agent SVC | `nil` |
|
||||
| `agent.service.binaryPort` | jaeger.thrift over binary thrift | `6832` |
|
||||
| `agent.service.compactPort` | jaeger.thrift over compact thrift | `6831` |
|
||||
| `agent.service.zipkinThriftPort` | zipkin.thrift over compact thrift | `5775` |
|
||||
| `agent.extraConfigmapMounts` | Additional agent configMap mounts | `[]` |
|
||||
| `agent.extraSecretMounts` | Additional agent secret mounts | `[]` |
|
||||
| `agent.useHostNetwork` | Enable hostNetwork for agents | `false` |
|
||||
| `agent.priorityClassName` | Priority class name for the agent pods | `nil` |
|
||||
| `collector.autoscaling.enabled` | Enable horizontal pod autoscaling | `false` |
|
||||
| `collector.autoscaling.minReplicas` | Minimum replicas | 2 |
|
||||
| `collector.autoscaling.maxReplicas` | Maximum replicas | 10 |
|
||||
| `collector.autoscaling.targetCPUUtilizationPercentage` | Target CPU utilization | 80 |
|
||||
| `collector.autoscaling.targetMemoryUtilizationPercentage` | Target memory utilization | `nil` |
|
||||
| `collector.image` | Image for jaeger collector | `jaegertracing/jaeger-collector` |
|
||||
| `collector.imagePullSecrets` | Secret to pull the Image for Jaeger Collector | `[]` |
|
||||
| `collector.pullPolicy` | Collector image pullPolicy | `IfNotPresent` |
|
||||
| `collector.service.annotations` | Annotations for Collector SVC | `nil` |
|
||||
| `collector.service.grpc.port` | Jaeger Agent port for model.proto | `14250` |
|
||||
| `collector.service.http.port` | Client port for HTTP thrift | `14268` |
|
||||
| `collector.service.loadBalancerSourceRanges` | list of IP CIDRs allowed access to load balancer (if supported) | `[]` |
|
||||
| `collector.service.type` | Service type | `ClusterIP` |
|
||||
| `collector.service.zipkin.port` | Zipkin port for JSON/thrift HTTP | `nil` |
|
||||
| `collector.extraConfigmapMounts` | Additional collector configMap mounts | `[]` |
|
||||
| `collector.extraSecretMounts` | Additional collector secret mounts | `[]` |
|
||||
| `collector.samplingConfig` | [Sampling strategies json file](https://www.jaegertracing.io/docs/latest/sampling/#collector-sampling-configuration) | `nil` |
|
||||
| `collector.priorityClassName` | Priority class name for the collector pods | `nil` |
|
||||
| `ingester.enabled` | Enable ingester component, collectors will write to Kafka | `false` |
|
||||
| `ingester.autoscaling.enabled` | Enable horizontal pod autoscaling | `false` |
|
||||
| `ingester.autoscaling.minReplicas` | Minimum replicas | 2 |
|
||||
| `ingester.autoscaling.maxReplicas` | Maximum replicas | 10 |
|
||||
| `ingester.autoscaling.targetCPUUtilizationPercentage` | Target CPU utilization | 80 |
|
||||
| `ingester.autoscaling.targetMemoryUtilizationPercentage` | Target memory utilization | `nil` |
|
||||
| `ingester.service.annotations` | Annotations for Ingester SVC | `nil` |
|
||||
| `ingester.image` | Image for jaeger Ingester | `jaegertracing/jaeger-ingester` |
|
||||
| `ingester.imagePullSecrets` | Secret to pull the Image for Jaeger Ingester | `[]` |
|
||||
| `ingester.pullPolicy` | Ingester image pullPolicy | `IfNotPresent` |
|
||||
| `ingester.service.annotations` | Annotations for Ingester SVC | `nil` |
|
||||
| `ingester.service.loadBalancerSourceRanges` | list of IP CIDRs allowed access to load balancer (if supported) | `[]` |
|
||||
| `ingester.service.type` | Service type | `ClusterIP` |
|
||||
| `ingester.extraConfigmapMounts` | Additional Ingester configMap mounts | `[]` |
|
||||
| `ingester.extraSecretMounts` | Additional Ingester secret mounts | `[]` |
|
||||
| `fullnameOverride` | Override full name | `nil` |
|
||||
| `hotrod.enabled` | Enables the Hotrod demo app | `false` |
|
||||
| `hotrod.service.loadBalancerSourceRanges` | list of IP CIDRs allowed access to load balancer (if supported) | `[]` |
|
||||
| `hotrod.image.pullSecrets` | Secret to pull the Image for the Hotrod demo app | `[]` |
|
||||
| `nameOverride` | Override name| `nil` |
|
||||
| `provisionDataStore.cassandra` | Provision Cassandra Data Store| `true` |
|
||||
| `provisionDataStore.elasticsearch` | Provision Elasticsearch Data Store | `false` |
|
||||
| `provisionDataStore.kafka` | Provision Kafka Data Store | `false` |
|
||||
| `query.agentSidecar.enabled` | Enable agent sidecare for query deployment | `true` |
|
||||
| `query.config` | [UI Config json file](https://www.jaegertracing.io/docs/latest/frontend-ui/) | `nil` |
|
||||
| `query.service.annotations` | Annotations for Query SVC | `nil` |
|
||||
| `query.image` | Image for Jaeger Query UI | `jaegertracing/jaeger-query` |
|
||||
| `query.imagePullSecrets` | Secret to pull the Image for Jaeger Query UI | `[]` |
|
||||
| `query.ingress.enabled` | Allow external traffic access | `false` |
|
||||
| `query.ingress.annotations` | Configure annotations for Ingress | `{}` |
|
||||
| `query.ingress.hosts` | Configure host for Ingress | `nil` |
|
||||
| `query.ingress.tls` | Configure tls for Ingress | `nil` |
|
||||
| `query.pullPolicy` | Query UI image pullPolicy | `IfNotPresent` |
|
||||
| `query.service.loadBalancerSourceRanges` | list of IP CIDRs allowed access to load balancer (if supported) | `[]` |
|
||||
| `query.service.nodePort` | Specific node port to use when type is NodePort | `nil` |
|
||||
| `query.service.port` | External accessible port | `80` |
|
||||
| `query.service.type` | Service type | `ClusterIP` |
|
||||
| `query.basePath` | Base path of Query UI, used for ingress as well (if it is enabled) | `/` |
|
||||
| `query.extraConfigmapMounts` | Additional query configMap mounts | `[]` |
|
||||
| `query.priorityClassName` | Priority class name for the Query UI pods | `nil` |
|
||||
| `schema.annotations` | Annotations for the schema job| `nil` |
|
||||
| `schema.extraConfigmapMounts` | Additional cassandra schema job configMap mounts | `[]` |
|
||||
| `schema.image` | Image to setup cassandra schema | `jaegertracing/jaeger-cassandra-schema` |
|
||||
| `schema.imagePullSecrets` | Secret to pull the Image for the Cassandra schema setup job | `[]` |
|
||||
| `schema.pullPolicy` | Schema image pullPolicy | `IfNotPresent` |
|
||||
| `schema.activeDeadlineSeconds` | Deadline in seconds for cassandra schema creation job to complete | `120` |
|
||||
| `schema.keyspace` | Set explicit keyspace name | `nil` |
|
||||
| `spark.enabled` | Enables the dependencies job| `false` |
|
||||
| `spark.image` | Image for the dependencies job| `jaegertracing/spark-dependencies` |
|
||||
| `spark.imagePullSecrets` | Secret to pull the Image for the Spark dependencies job | `[]` |
|
||||
| `spark.pullPolicy` | Image pull policy of the deps image | `Always` |
|
||||
| `spark.schedule` | Schedule of the cron job | `"49 23 * * *"` |
|
||||
| `spark.successfulJobsHistoryLimit` | Cron job successfulJobsHistoryLimit | `5` |
|
||||
| `spark.failedJobsHistoryLimit` | Cron job failedJobsHistoryLimit | `5` |
|
||||
| `spark.tag` | Tag of the dependencies job image | `latest` |
|
||||
| `spark.extraConfigmapMounts` | Additional spark configMap mounts | `[]` |
|
||||
| `spark.extraSecretMounts` | Additional spark secret mounts | `[]` |
|
||||
| `esIndexCleaner.enabled` | Enables the ElasticSearch indices cleanup job| `false` |
|
||||
| `esIndexCleaner.image` | Image for the ElasticSearch indices cleanup job| `jaegertracing/jaeger-es-index-cleaner` |
|
||||
| `esIndexCleaner.imagePullSecrets` | Secret to pull the Image for the ElasticSearch indices cleanup job | `[]` |
|
||||
| `esIndexCleaner.pullPolicy` | Image pull policy of the ES cleanup image | `Always` |
|
||||
| `esIndexCleaner.numberOfDays` | ElasticSearch indices older than this number (Number of days) would be deleted by the CronJob | `7`
|
||||
| `esIndexCleaner.schedule` | Schedule of the cron job | `"55 23 * * *"` |
|
||||
| `esIndexCleaner.successfulJobsHistoryLimit` | successfulJobsHistoryLimit for ElasticSearch indices cleanup CronJob | `5` |
|
||||
| `esIndexCleaner.failedJobsHistoryLimit` | failedJobsHistoryLimit for ElasticSearch indices cleanup CronJob | `5` |
|
||||
| `esIndexCleaner.tag` | Tag of the dependencies job image | `latest` |
|
||||
| `esIndexCleaner.extraConfigmapMounts` | Additional esIndexCleaner configMap mounts | `[]` |
|
||||
| `esIndexCleaner.extraSecretMounts` | Additional esIndexCleaner secret mounts | `[]` |
|
||||
| `storage.cassandra.env` | Extra cassandra related env vars to be configured on components that talk to cassandra | `cassandra` |
|
||||
| `storage.cassandra.cmdlineParams` | Extra cassandra related command line options to be configured on components that talk to cassandra | `cassandra` |
|
||||
| `storage.cassandra.existingSecret` | Name of existing password secret object (for password authentication | `nil`
|
||||
| `storage.cassandra.host` | Provisioned cassandra host | `cassandra` |
|
||||
| `storage.cassandra.keyspace` | Schema name for cassandra | `jaeger_v1_test` |
|
||||
| `storage.cassandra.password` | Provisioned cassandra password (ignored if storage.cassandra.existingSecret set) | `password` |
|
||||
| `storage.cassandra.port` | Provisioned cassandra port | `9042` |
|
||||
| `storage.cassandra.tls.enabled` | Provisioned cassandra TLS connection enabled | `false` |
|
||||
| `storage.cassandra.tls.secretName` | Provisioned cassandra TLS connection existing secret name (possible keys in secret: `ca-cert.pem`, `client-key.pem`, `client-cert.pem`, `cqlshrc`, `commonName`) | `` |
|
||||
| `storage.cassandra.usePassword` | Use password | `true` |
|
||||
| `storage.cassandra.user` | Provisioned cassandra username | `user` |
|
||||
| `storage.elasticsearch.env` | Extra ES related env vars to be configured on components that talk to ES | `nil` |
|
||||
| `storage.elasticsearch.cmdlineParams` | Extra ES related command line options to be configured on components that talk to ES | `nil` |
|
||||
| `storage.elasticsearch.existingSecret` | Name of existing password secret object (for password authentication | `nil` |
|
||||
| `storage.elasticsearch.existingSecretKey` | Key of the declared password secret | `password` |
|
||||
| `storage.elasticsearch.host` | Provisioned elasticsearch host| `elasticsearch` |
|
||||
| `storage.elasticsearch.password` | Provisioned elasticsearch password (ignored if storage.elasticsearch.existingSecret set | `changeme` |
|
||||
| `storage.elasticsearch.port` | Provisioned elasticsearch port| `9200` |
|
||||
| `storage.elasticsearch.scheme` | Provisioned elasticsearch scheme | `http` |
|
||||
| `storage.elasticsearch.usePassword` | Use password | `true` |
|
||||
| `storage.elasticsearch.user` | Provisioned elasticsearch user| `elastic` |
|
||||
| `storage.elasticsearch.indexPrefix` | Index Prefix for elasticsearch | `nil` |
|
||||
| `storage.elasticsearch.nodesWanOnly` | Only access specified es host | `false` |
|
||||
| `storage.kafka.authentication` | Authentication type used to authenticate with kafka cluster. e.g. none, kerberos, tls | `none` |
|
||||
| `storage.kafka.brokers` | Broker List for Kafka with port | `kafka:9092` |
|
||||
| `storage.kafka.topic` | Topic name for Kafka | `jaeger_v1_test` |
|
||||
| `storage.type` | Storage type (ES or Cassandra)| `cassandra` |
|
||||
| `tag` | Image tag/version | `1.18.0` |
|
||||
|
||||
For more information about some of the tunable parameters that Cassandra provides, please visit the helm chart for [cassandra](https://github.com/kubernetes/charts/tree/master/incubator/cassandra) and the official [website](http://cassandra.apache.org/) at apache.org.
|
||||
|
||||
For more information about some of the tunable parameters that Jaeger provides, please visit the official [Jaeger repo](https://github.com/uber/jaeger) at GitHub.com.
|
||||
|
||||
### Pending enhancements
|
||||
|
||||
- [ ] Sidecar deployment support
|
||||
Binary file not shown.
|
|
@ -1,17 +0,0 @@
|
|||
# Patterns to ignore when building packages.
|
||||
# This supports shell glob matching, relative path matching, and
|
||||
# negation (prefixed with !). Only one pattern per line.
|
||||
.DS_Store
|
||||
# Common VCS dirs
|
||||
.git/
|
||||
.gitignore
|
||||
# Common backup files
|
||||
*.swp
|
||||
*.bak
|
||||
*.tmp
|
||||
*~
|
||||
# Various IDEs
|
||||
.project
|
||||
.idea/
|
||||
*.tmproj
|
||||
OWNERS
|
||||
|
|
@ -1,19 +0,0 @@
|
|||
apiVersion: v1
|
||||
appVersion: 3.11.6
|
||||
description: Apache Cassandra is a free and open-source distributed database management
|
||||
system designed to handle large amounts of data across many commodity servers, providing
|
||||
high availability with no single point of failure.
|
||||
engine: gotpl
|
||||
home: http://cassandra.apache.org
|
||||
icon: https://upload.wikimedia.org/wikipedia/commons/thumb/5/5e/Cassandra_logo.svg/330px-Cassandra_logo.svg.png
|
||||
keywords:
|
||||
- cassandra
|
||||
- database
|
||||
- nosql
|
||||
maintainers:
|
||||
- email: goonohc@gmail.com
|
||||
name: KongZ
|
||||
- email: maor.friedman@redhat.com
|
||||
name: maorfr
|
||||
name: cassandra
|
||||
version: 0.15.2
|
||||
|
|
@ -1,218 +0,0 @@
|
|||
# Cassandra
|
||||
A Cassandra Chart for Kubernetes
|
||||
|
||||
## Install Chart
|
||||
To install the Cassandra Chart into your Kubernetes cluster (This Chart requires persistent volume by default, you may need to create a storage class before install chart. To create storage class, see [Persist data](#persist_data) section)
|
||||
|
||||
```bash
|
||||
helm install --namespace "cassandra" -n "cassandra" incubator/cassandra
|
||||
```
|
||||
|
||||
After installation succeeds, you can get a status of Chart
|
||||
|
||||
```bash
|
||||
helm status "cassandra"
|
||||
```
|
||||
|
||||
If you want to delete your Chart, use this command
|
||||
```bash
|
||||
helm delete --purge "cassandra"
|
||||
```
|
||||
|
||||
## Upgrading
|
||||
|
||||
To upgrade your Cassandra release, simply run
|
||||
|
||||
```bash
|
||||
helm upgrade "cassandra" incubator/cassandra
|
||||
```
|
||||
|
||||
### 0.12.0
|
||||
|
||||
This version fixes https://github.com/helm/charts/issues/7803 by removing mutable labels in `spec.VolumeClaimTemplate.metadata.labels` so that it is upgradable.
|
||||
|
||||
Until this version, in order to upgrade, you have to delete the Cassandra StatefulSet before upgrading:
|
||||
```bash
|
||||
$ kubectl delete statefulset --cascade=false my-cassandra-release
|
||||
```
|
||||
|
||||
|
||||
## Persist data
|
||||
You need to create `StorageClass` before able to persist data in persistent volume.
|
||||
To create a `StorageClass` on Google Cloud, run the following
|
||||
|
||||
```bash
|
||||
kubectl create -f sample/create-storage-gce.yaml
|
||||
```
|
||||
|
||||
And set the following values in `values.yaml`
|
||||
|
||||
```yaml
|
||||
persistence:
|
||||
enabled: true
|
||||
```
|
||||
|
||||
If you want to create a `StorageClass` on other platform, please see documentation here [https://kubernetes.io/docs/user-guide/persistent-volumes/](https://kubernetes.io/docs/user-guide/persistent-volumes/)
|
||||
|
||||
When running a cluster without persistence, the termination of a pod will first initiate a decommissioning of that pod.
|
||||
Depending on the amount of data stored inside the cluster this may take a while. In order to complete a graceful
|
||||
termination, pods need to get more time for it. Set the following values in `values.yaml`:
|
||||
|
||||
```yaml
|
||||
podSettings:
|
||||
terminationGracePeriodSeconds: 1800
|
||||
```
|
||||
|
||||
## Install Chart with specific cluster size
|
||||
By default, this Chart will create a cassandra with 3 nodes. If you want to change the cluster size during installation, you can use `--set config.cluster_size={value}` argument. Or edit `values.yaml`
|
||||
|
||||
For example:
|
||||
Set cluster size to 5
|
||||
|
||||
```bash
|
||||
helm install --namespace "cassandra" -n "cassandra" --set config.cluster_size=5 incubator/cassandra/
|
||||
```
|
||||
|
||||
## Install Chart with specific resource size
|
||||
By default, this Chart will create a cassandra with CPU 2 vCPU and 4Gi of memory which is suitable for development environment.
|
||||
If you want to use this Chart for production, I would recommend to update the CPU to 4 vCPU and 16Gi. Also increase size of `max_heap_size` and `heap_new_size`.
|
||||
To update the settings, edit `values.yaml`
|
||||
|
||||
## Install Chart with specific node
|
||||
Sometime you may need to deploy your cassandra to specific nodes to allocate resources. You can use node selector by edit `nodes.enabled=true` in `values.yaml`
|
||||
For example, you have 6 vms in node pools and you want to deploy cassandra to node which labeled as `cloud.google.com/gke-nodepool: pool-db`
|
||||
|
||||
Set the following values in `values.yaml`
|
||||
|
||||
```yaml
|
||||
nodes:
|
||||
enabled: true
|
||||
selector:
|
||||
nodeSelector:
|
||||
cloud.google.com/gke-nodepool: pool-db
|
||||
```
|
||||
|
||||
## Configuration
|
||||
|
||||
The following table lists the configurable parameters of the Cassandra chart and their default values.
|
||||
|
||||
| Parameter | Description | Default |
|
||||
| ----------------------- | --------------------------------------------- | ---------------------------------------------------------- |
|
||||
| `image.repo` | `cassandra` image repository | `cassandra` |
|
||||
| `image.tag` | `cassandra` image tag | `3.11.5` |
|
||||
| `image.pullPolicy` | Image pull policy | `Always` if `imageTag` is `latest`, else `IfNotPresent` |
|
||||
| `image.pullSecrets` | Image pull secrets | `nil` |
|
||||
| `config.cluster_domain` | The name of the cluster domain. | `cluster.local` |
|
||||
| `config.cluster_name` | The name of the cluster. | `cassandra` |
|
||||
| `config.cluster_size` | The number of nodes in the cluster. | `3` |
|
||||
| `config.seed_size` | The number of seed nodes used to bootstrap new clients joining the cluster. | `2` |
|
||||
| `config.seeds` | The comma-separated list of seed nodes. | Automatically generated according to `.Release.Name` and `config.seed_size` |
|
||||
| `config.num_tokens` | Initdb Arguments | `256` |
|
||||
| `config.dc_name` | Initdb Arguments | `DC1` |
|
||||
| `config.rack_name` | Initdb Arguments | `RAC1` |
|
||||
| `config.endpoint_snitch` | Initdb Arguments | `SimpleSnitch` |
|
||||
| `config.max_heap_size` | Initdb Arguments | `2048M` |
|
||||
| `config.heap_new_size` | Initdb Arguments | `512M` |
|
||||
| `config.ports.cql` | Initdb Arguments | `9042` |
|
||||
| `config.ports.thrift` | Initdb Arguments | `9160` |
|
||||
| `config.ports.agent` | The port of the JVM Agent (if any) | `nil` |
|
||||
| `config.start_rpc` | Initdb Arguments | `false` |
|
||||
| `configOverrides` | Overrides config files in /etc/cassandra dir | `{}` |
|
||||
| `commandOverrides` | Overrides default docker command | `[]` |
|
||||
| `argsOverrides` | Overrides default docker args | `[]` |
|
||||
| `env` | Custom env variables | `{}` |
|
||||
| `schedulerName` | Name of k8s scheduler (other than the default) | `nil` |
|
||||
| `persistence.enabled` | Use a PVC to persist data | `true` |
|
||||
| `persistence.storageClass` | Storage class of backing PVC | `nil` (uses alpha storage class annotation) |
|
||||
| `persistence.accessMode` | Use volume as ReadOnly or ReadWrite | `ReadWriteOnce` |
|
||||
| `persistence.size` | Size of data volume | `10Gi` |
|
||||
| `resources` | CPU/Memory resource requests/limits | Memory: `4Gi`, CPU: `2` |
|
||||
| `service.type` | k8s service type exposing ports, e.g. `NodePort`| `ClusterIP` |
|
||||
| `service.annotations` | Annotations to apply to cassandra service | `""` |
|
||||
| `podManagementPolicy` | podManagementPolicy of the StatefulSet | `OrderedReady` |
|
||||
| `podDisruptionBudget` | Pod distruption budget | `{}` |
|
||||
| `podAnnotations` | pod annotations for the StatefulSet | `{}` |
|
||||
| `updateStrategy.type` | UpdateStrategy of the StatefulSet | `OnDelete` |
|
||||
| `livenessProbe.initialDelaySeconds` | Delay before liveness probe is initiated | `90` |
|
||||
| `livenessProbe.periodSeconds` | How often to perform the probe | `30` |
|
||||
| `livenessProbe.timeoutSeconds` | When the probe times out | `5` |
|
||||
| `livenessProbe.successThreshold` | Minimum consecutive successes for the probe to be considered successful after having failed. | `1` |
|
||||
| `livenessProbe.failureThreshold` | Minimum consecutive failures for the probe to be considered failed after having succeeded. | `3` |
|
||||
| `readinessProbe.initialDelaySeconds` | Delay before readiness probe is initiated | `90` |
|
||||
| `readinessProbe.periodSeconds` | How often to perform the probe | `30` |
|
||||
| `readinessProbe.timeoutSeconds` | When the probe times out | `5` |
|
||||
| `readinessProbe.successThreshold` | Minimum consecutive successes for the probe to be considered successful after having failed. | `1` |
|
||||
| `readinessProbe.failureThreshold` | Minimum consecutive failures for the probe to be considered failed after having succeeded. | `3` |
|
||||
| `readinessProbe.address` | Address to use for checking node has joined the cluster and is ready. | `${POD_IP}` |
|
||||
| `rbac.create` | Specifies whether RBAC resources should be created | `true` |
|
||||
| `serviceAccount.create` | Specifies whether a ServiceAccount should be created | `true` |
|
||||
| `serviceAccount.name` | The name of the ServiceAccount to use | |
|
||||
| `backup.enabled` | Enable backup on chart installation | `false` |
|
||||
| `backup.schedule` | Keyspaces to backup, each with cron time | |
|
||||
| `backup.annotations` | Backup pod annotations | iam.amazonaws.com/role: `cain` |
|
||||
| `backup.image.repository` | Backup image repository | `maorfr/cain` |
|
||||
| `backup.image.tag` | Backup image tag | `0.6.0` |
|
||||
| `backup.extraArgs` | Additional arguments for cain | `[]` |
|
||||
| `backup.env` | Backup environment variables | AWS_REGION: `us-east-1` |
|
||||
| `backup.resources` | Backup CPU/Memory resource requests/limits | Memory: `1Gi`, CPU: `1` |
|
||||
| `backup.destination` | Destination to store backup artifacts | `s3://bucket/cassandra` |
|
||||
| `backup.google.serviceAccountSecret` | Secret containing credentials if GCS is used as destination | |
|
||||
| `exporter.enabled` | Enable Cassandra exporter | `false` |
|
||||
| `exporter.servicemonitor.enabled` | Enable ServiceMonitor for exporter | `true` |
|
||||
| `exporter.servicemonitor.additionalLabels`| Additional labels for Service Monitor | `{}` |
|
||||
| `exporter.image.repo` | Exporter image repository | `criteord/cassandra_exporter` |
|
||||
| `exporter.image.tag` | Exporter image tag | `2.0.2` |
|
||||
| `exporter.port` | Exporter port | `5556` |
|
||||
| `exporter.jvmOpts` | Exporter additional JVM options | |
|
||||
| `exporter.resources` | Exporter CPU/Memory resource requests/limits | `{}` |
|
||||
| `extraContainers` | Sidecar containers for the pods | `[]` |
|
||||
| `extraVolumes` | Additional volumes for the pods | `[]` |
|
||||
| `extraVolumeMounts` | Extra volume mounts for the pods | `[]` |
|
||||
| `affinity` | Kubernetes node affinity | `{}` |
|
||||
| `tolerations` | Kubernetes node tolerations | `[]` |
|
||||
|
||||
|
||||
## Scale cassandra
|
||||
When you want to change the cluster size of your cassandra, you can use the helm upgrade command.
|
||||
|
||||
```bash
|
||||
helm upgrade --set config.cluster_size=5 cassandra incubator/cassandra
|
||||
```
|
||||
|
||||
## Get cassandra status
|
||||
You can get your cassandra cluster status by running the command
|
||||
|
||||
```bash
|
||||
kubectl exec -it --namespace cassandra $(kubectl get pods --namespace cassandra -l app=cassandra-cassandra -o jsonpath='{.items[0].metadata.name}') nodetool status
|
||||
```
|
||||
|
||||
Output
|
||||
```bash
|
||||
Datacenter: asia-east1
|
||||
======================
|
||||
Status=Up/Down
|
||||
|/ State=Normal/Leaving/Joining/Moving
|
||||
-- Address Load Tokens Owns (effective) Host ID Rack
|
||||
UN 10.8.1.11 108.45 KiB 256 66.1% 410cc9da-8993-4dc2-9026-1dd381874c54 a
|
||||
UN 10.8.4.12 84.08 KiB 256 68.7% 96e159e1-ef94-406e-a0be-e58fbd32a830 c
|
||||
UN 10.8.3.6 103.07 KiB 256 65.2% 1a42b953-8728-4139-b070-b855b8fff326 b
|
||||
```
|
||||
|
||||
## Benchmark
|
||||
You can use [cassandra-stress](https://docs.datastax.com/en/cassandra/3.0/cassandra/tools/toolsCStress.html) tool to run the benchmark on the cluster by the following command
|
||||
|
||||
```bash
|
||||
kubectl exec -it --namespace cassandra $(kubectl get pods --namespace cassandra -l app=cassandra-cassandra -o jsonpath='{.items[0].metadata.name}') cassandra-stress
|
||||
```
|
||||
|
||||
Example of `cassandra-stress` argument
|
||||
- Run both read and write with ration 9:1
|
||||
- Operator total 1 million keys with uniform distribution
|
||||
- Use QUORUM for read/write
|
||||
- Generate 50 threads
|
||||
- Generate result in graph
|
||||
- Use NetworkTopologyStrategy with replica factor 2
|
||||
|
||||
```bash
|
||||
cassandra-stress mixed ratio\(write=1,read=9\) n=1000000 cl=QUORUM -pop dist=UNIFORM\(1..1000000\) -mode native cql3 -rate threads=50 -log file=~/mixed_autorate_r9w1_1M.log -graph file=test2.html title=test revision=test2 -schema "replication(strategy=NetworkTopologyStrategy, factor=2)"
|
||||
```
|
||||
|
|
@ -1,7 +0,0 @@
|
|||
kind: StorageClass
|
||||
apiVersion: storage.k8s.io/v1
|
||||
metadata:
|
||||
name: generic
|
||||
provisioner: kubernetes.io/gce-pd
|
||||
parameters:
|
||||
type: pd-ssd
|
||||
|
|
@ -1,35 +0,0 @@
|
|||
Cassandra CQL can be accessed via port {{ .Values.config.ports.cql }} on the following DNS name from within your cluster:
|
||||
Cassandra Thrift can be accessed via port {{ .Values.config.ports.thrift }} on the following DNS name from within your cluster:
|
||||
|
||||
If you want to connect to the remote instance with your local Cassandra CQL cli. To forward the API port to localhost:9042 run the following:
|
||||
- kubectl port-forward --namespace {{ .Release.Namespace }} $(kubectl get pods --namespace {{ .Release.Namespace }} -l app={{ template "cassandra.name" . }},release={{ .Release.Name }} -o jsonpath='{ .items[0].metadata.name }') 9042:{{ .Values.config.ports.cql }}
|
||||
|
||||
If you want to connect to the Cassandra CQL run the following:
|
||||
{{- if contains "NodePort" .Values.service.type }}
|
||||
- export CQL_PORT=$(kubectl get --namespace {{ .Release.Namespace }} -o jsonpath="{.spec.ports[0].nodePort}" services {{ template "cassandra.fullname" . }})
|
||||
- export CQL_HOST=$(kubectl get nodes --namespace {{ .Release.Namespace }} -o jsonpath="{.items[0].status.addresses[0].address}")
|
||||
- cqlsh $CQL_HOST $CQL_PORT
|
||||
|
||||
{{- else if contains "LoadBalancer" .Values.service.type }}
|
||||
NOTE: It may take a few minutes for the LoadBalancer IP to be available.
|
||||
Watch the status with: 'kubectl get svc --namespace {{ .Release.Namespace }} -w {{ template "cassandra.fullname" . }}'
|
||||
- export SERVICE_IP=$(kubectl get svc --namespace {{ .Release.Namespace }} {{ template "cassandra.fullname" . }} -o jsonpath='{.status.loadBalancer.ingress[0].ip}')
|
||||
- echo cqlsh $SERVICE_IP
|
||||
{{- else if contains "ClusterIP" .Values.service.type }}
|
||||
- kubectl port-forward --namespace {{ .Release.Namespace }} $(kubectl get pods --namespace {{ .Release.Namespace }} -l "app={{ template "cassandra.name" . }},release={{ .Release.Name }}" -o jsonpath="{.items[0].metadata.name}") 9042:{{ .Values.config.ports.cql }}
|
||||
echo cqlsh 127.0.0.1 9042
|
||||
{{- end }}
|
||||
|
||||
You can also see the cluster status by run the following:
|
||||
- kubectl exec -it --namespace {{ .Release.Namespace }} $(kubectl get pods --namespace {{ .Release.Namespace }} -l app={{ template "cassandra.name" . }},release={{ .Release.Name }} -o jsonpath='{.items[0].metadata.name}') nodetool status
|
||||
|
||||
To tail the logs for the Cassandra pod run the following:
|
||||
- kubectl logs -f --namespace {{ .Release.Namespace }} $(kubectl get pods --namespace {{ .Release.Namespace }} -l app={{ template "cassandra.name" . }},release={{ .Release.Name }} -o jsonpath='{ .items[0].metadata.name }')
|
||||
|
||||
{{- if not .Values.persistence.enabled }}
|
||||
|
||||
Note that the cluster is running with node-local storage instead of PersistentVolumes. In order to prevent data loss,
|
||||
pods will be decommissioned upon termination. Decommissioning may take some time, so you might also want to adjust the
|
||||
pod termination gace period, which is currently set to {{ .Values.podSettings.terminationGracePeriodSeconds }} seconds.
|
||||
|
||||
{{- end}}
|
||||
|
|
@ -1,43 +0,0 @@
|
|||
{{/* vim: set filetype=mustache: */}}
|
||||
{{/*
|
||||
Expand the name of the chart.
|
||||
*/}}
|
||||
{{- define "cassandra.name" -}}
|
||||
{{- default .Chart.Name .Values.nameOverride | trunc 63 | trimSuffix "-" -}}
|
||||
{{- end -}}
|
||||
|
||||
{{/*
|
||||
Create a default fully qualified app name.
|
||||
We truncate at 63 chars because some Kubernetes name fields are limited to this (by the DNS naming spec).
|
||||
If release name contains chart name it will be used as a full name.
|
||||
*/}}
|
||||
{{- define "cassandra.fullname" -}}
|
||||
{{- if .Values.fullnameOverride -}}
|
||||
{{- .Values.fullnameOverride | trunc 63 | trimSuffix "-" -}}
|
||||
{{- else -}}
|
||||
{{- $name := default .Chart.Name .Values.nameOverride -}}
|
||||
{{- if contains $name .Release.Name -}}
|
||||
{{- .Release.Name | trunc 63 | trimSuffix "-" -}}
|
||||
{{- else -}}
|
||||
{{- printf "%s-%s" .Release.Name $name | trunc 63 | trimSuffix "-" -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
|
||||
{{/*
|
||||
Create chart name and version as used by the chart label.
|
||||
*/}}
|
||||
{{- define "cassandra.chart" -}}
|
||||
{{- printf "%s-%s" .Chart.Name .Chart.Version | replace "+" "_" | trunc 63 | trimSuffix "-" -}}
|
||||
{{- end -}}
|
||||
|
||||
{{/*
|
||||
Create the name of the service account to use
|
||||
*/}}
|
||||
{{- define "cassandra.serviceAccountName" -}}
|
||||
{{- if .Values.serviceAccount.create -}}
|
||||
{{ default (include "cassandra.fullname" .) .Values.serviceAccount.name }}
|
||||
{{- else -}}
|
||||
{{ default "default" .Values.serviceAccount.name }}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
|
|
@ -1,90 +0,0 @@
|
|||
{{- if .Values.backup.enabled }}
|
||||
{{- $release := .Release }}
|
||||
{{- $values := .Values }}
|
||||
{{- $backup := $values.backup }}
|
||||
{{- range $index, $schedule := $backup.schedule }}
|
||||
---
|
||||
apiVersion: batch/v1beta1
|
||||
kind: CronJob
|
||||
metadata:
|
||||
name: {{ template "cassandra.fullname" $ }}-backup-{{ $schedule.keyspace | replace "_" "-" }}
|
||||
labels:
|
||||
app: {{ template "cassandra.name" $ }}-cain
|
||||
chart: {{ template "cassandra.chart" $ }}
|
||||
release: "{{ $release.Name }}"
|
||||
heritage: "{{ $release.Service }}"
|
||||
spec:
|
||||
schedule: {{ $schedule.cron | quote }}
|
||||
concurrencyPolicy: Forbid
|
||||
startingDeadlineSeconds: 120
|
||||
jobTemplate:
|
||||
spec:
|
||||
template:
|
||||
metadata:
|
||||
annotations:
|
||||
{{ toYaml $backup.annotations }}
|
||||
spec:
|
||||
restartPolicy: OnFailure
|
||||
serviceAccountName: {{ template "cassandra.serviceAccountName" $ }}
|
||||
containers:
|
||||
- name: cassandra-backup
|
||||
image: "{{ $backup.image.repository }}:{{ $backup.image.tag }}"
|
||||
command: ["cain"]
|
||||
args:
|
||||
- backup
|
||||
- --namespace
|
||||
- {{ $release.Namespace }}
|
||||
- --selector
|
||||
- release={{ $release.Name }},app={{ template "cassandra.name" $ }}
|
||||
- --keyspace
|
||||
- {{ $schedule.keyspace }}
|
||||
- --dst
|
||||
- {{ $backup.destination }}
|
||||
{{- with $backup.extraArgs }}
|
||||
{{ toYaml . | indent 12 }}
|
||||
{{- end }}
|
||||
env:
|
||||
{{- if $backup.google.serviceAccountSecret }}
|
||||
- name: GOOGLE_APPLICATION_CREDENTIALS
|
||||
value: "/etc/secrets/google/credentials.json"
|
||||
{{- end }}
|
||||
{{- with $backup.env }}
|
||||
{{ toYaml . | indent 12 }}
|
||||
{{- end }}
|
||||
{{- with $backup.resources }}
|
||||
resources:
|
||||
{{ toYaml . | indent 14 }}
|
||||
{{- end }}
|
||||
{{- if $backup.google.serviceAccountSecret }}
|
||||
volumeMounts:
|
||||
- name: google-service-account
|
||||
mountPath: /etc/secrets/google/
|
||||
{{- end }}
|
||||
{{- if $backup.google.serviceAccountSecret }}
|
||||
volumes:
|
||||
- name: google-service-account
|
||||
secret:
|
||||
secretName: {{ $backup.google.serviceAccountSecret | quote }}
|
||||
{{- end }}
|
||||
affinity:
|
||||
podAffinity:
|
||||
preferredDuringSchedulingIgnoredDuringExecution:
|
||||
- weight: 1
|
||||
podAffinityTerm:
|
||||
labelSelector:
|
||||
matchExpressions:
|
||||
- key: app
|
||||
operator: In
|
||||
values:
|
||||
- {{ template "cassandra.fullname" $ }}
|
||||
- key: release
|
||||
operator: In
|
||||
values:
|
||||
- {{ $release.Name }}
|
||||
topologyKey: "kubernetes.io/hostname"
|
||||
{{- with $values.tolerations }}
|
||||
tolerations:
|
||||
{{ toYaml . | indent 12 }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
|
|
@ -1,50 +0,0 @@
|
|||
{{- if .Values.backup.enabled }}
|
||||
{{- if .Values.serviceAccount.create }}
|
||||
apiVersion: v1
|
||||
kind: ServiceAccount
|
||||
metadata:
|
||||
name: {{ template "cassandra.serviceAccountName" . }}
|
||||
labels:
|
||||
app: {{ template "cassandra.name" . }}
|
||||
chart: {{ template "cassandra.chart" . }}
|
||||
release: "{{ .Release.Name }}"
|
||||
heritage: "{{ .Release.Service }}"
|
||||
---
|
||||
{{- end }}
|
||||
{{- if .Values.rbac.create }}
|
||||
apiVersion: rbac.authorization.k8s.io/v1
|
||||
kind: Role
|
||||
metadata:
|
||||
name: {{ template "cassandra.fullname" . }}-backup
|
||||
labels:
|
||||
app: {{ template "cassandra.name" . }}
|
||||
chart: {{ template "cassandra.chart" . }}
|
||||
release: "{{ .Release.Name }}"
|
||||
heritage: "{{ .Release.Service }}"
|
||||
rules:
|
||||
- apiGroups: [""]
|
||||
resources: ["pods", "pods/log"]
|
||||
verbs: ["get", "list"]
|
||||
- apiGroups: [""]
|
||||
resources: ["pods/exec"]
|
||||
verbs: ["create"]
|
||||
---
|
||||
apiVersion: rbac.authorization.k8s.io/v1
|
||||
kind: RoleBinding
|
||||
metadata:
|
||||
name: {{ template "cassandra.fullname" . }}-backup
|
||||
labels:
|
||||
app: {{ template "cassandra.name" . }}
|
||||
chart: {{ template "cassandra.chart" . }}
|
||||
release: "{{ .Release.Name }}"
|
||||
heritage: "{{ .Release.Service }}"
|
||||
roleRef:
|
||||
apiGroup: rbac.authorization.k8s.io
|
||||
kind: Role
|
||||
name: {{ template "cassandra.fullname" . }}-backup
|
||||
subjects:
|
||||
- kind: ServiceAccount
|
||||
name: {{ template "cassandra.serviceAccountName" . }}
|
||||
namespace: {{ .Release.Namespace }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
|
|
@ -1,14 +0,0 @@
|
|||
{{- if .Values.configOverrides }}
|
||||
kind: ConfigMap
|
||||
apiVersion: v1
|
||||
metadata:
|
||||
name: {{ template "cassandra.name" . }}
|
||||
namespace: {{ .Release.Namespace }}
|
||||
labels:
|
||||
app: {{ template "cassandra.name" . }}
|
||||
chart: {{ .Chart.Name }}-{{ .Chart.Version | replace "+" "_" }}
|
||||
release: {{ .Release.Name }}
|
||||
heritage: {{ .Release.Service }}
|
||||
data:
|
||||
{{ toYaml .Values.configOverrides | indent 2 }}
|
||||
{{- end }}
|
||||
|
|
@ -1,18 +0,0 @@
|
|||
{{- if .Values.podDisruptionBudget -}}
|
||||
apiVersion: policy/v1beta1
|
||||
kind: PodDisruptionBudget
|
||||
metadata:
|
||||
labels:
|
||||
app: {{ template "cassandra.name" . }}
|
||||
chart: {{ .Chart.Name }}-{{ .Chart.Version }}
|
||||
heritage: {{ .Release.Service }}
|
||||
release: {{ .Release.Name }}
|
||||
name: {{ template "cassandra.fullname" . }}
|
||||
namespace: {{ .Release.Namespace }}
|
||||
spec:
|
||||
selector:
|
||||
matchLabels:
|
||||
app: {{ template "cassandra.name" . }}
|
||||
release: {{ .Release.Name }}
|
||||
{{ toYaml .Values.podDisruptionBudget | indent 2 }}
|
||||
{{- end -}}
|
||||
|
|
@ -1,46 +0,0 @@
|
|||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: {{ template "cassandra.fullname" . }}
|
||||
namespace: {{ .Release.Namespace }}
|
||||
labels:
|
||||
app: {{ template "cassandra.name" . }}
|
||||
chart: {{ template "cassandra.chart" . }}
|
||||
release: {{ .Release.Name }}
|
||||
heritage: {{ .Release.Service }}
|
||||
{{- with .Values.service.annotations }}
|
||||
annotations:
|
||||
{{- toYaml . | nindent 4 }}
|
||||
{{- end }}
|
||||
spec:
|
||||
clusterIP: None
|
||||
type: {{ .Values.service.type }}
|
||||
ports:
|
||||
{{- if .Values.exporter.enabled }}
|
||||
- name: metrics
|
||||
port: 5556
|
||||
targetPort: {{ .Values.exporter.port }}
|
||||
{{- end }}
|
||||
- name: intra
|
||||
port: 7000
|
||||
targetPort: 7000
|
||||
- name: tls
|
||||
port: 7001
|
||||
targetPort: 7001
|
||||
- name: jmx
|
||||
port: 7199
|
||||
targetPort: 7199
|
||||
- name: cql
|
||||
port: {{ default 9042 .Values.config.ports.cql }}
|
||||
targetPort: {{ default 9042 .Values.config.ports.cql }}
|
||||
- name: thrift
|
||||
port: {{ default 9160 .Values.config.ports.thrift }}
|
||||
targetPort: {{ default 9160 .Values.config.ports.thrift }}
|
||||
{{- if .Values.config.ports.agent }}
|
||||
- name: agent
|
||||
port: {{ .Values.config.ports.agent }}
|
||||
targetPort: {{ .Values.config.ports.agent }}
|
||||
{{- end }}
|
||||
selector:
|
||||
app: {{ template "cassandra.name" . }}
|
||||
release: {{ .Release.Name }}
|
||||
|
|
@ -1,25 +0,0 @@
|
|||
{{- if and .Values.exporter.enabled .Values.exporter.serviceMonitor.enabled }}
|
||||
apiVersion: monitoring.coreos.com/v1
|
||||
kind: ServiceMonitor
|
||||
metadata:
|
||||
name: {{ template "cassandra.fullname" . }}
|
||||
namespace: {{ .Release.Namespace }}
|
||||
labels:
|
||||
app: {{ template "cassandra.name" . }}
|
||||
chart: {{ template "cassandra.chart" . }}
|
||||
release: {{ .Release.Name }}
|
||||
heritage: {{ .Release.Service }}
|
||||
{{- if .Values.exporter.serviceMonitor.additionalLabels }}
|
||||
{{ toYaml .Values.exporter.serviceMonitor.additionalLabels | indent 4 }}
|
||||
{{- end }}
|
||||
spec:
|
||||
jobLabel: {{ template "cassandra.name" . }}
|
||||
endpoints:
|
||||
- port: metrics
|
||||
interval: 10s
|
||||
selector:
|
||||
matchLabels:
|
||||
app: {{ template "cassandra.name" . }}
|
||||
namespaceSelector:
|
||||
any: true
|
||||
{{- end }}
|
||||
|
|
@ -1,230 +0,0 @@
|
|||
apiVersion: apps/v1
|
||||
kind: StatefulSet
|
||||
metadata:
|
||||
name: {{ template "cassandra.fullname" . }}
|
||||
namespace: {{ .Release.Namespace }}
|
||||
labels:
|
||||
app: {{ template "cassandra.name" . }}
|
||||
chart: {{ template "cassandra.chart" . }}
|
||||
release: {{ .Release.Name }}
|
||||
heritage: {{ .Release.Service }}
|
||||
spec:
|
||||
selector:
|
||||
matchLabels:
|
||||
app: {{ template "cassandra.name" . }}
|
||||
release: {{ .Release.Name }}
|
||||
serviceName: {{ template "cassandra.fullname" . }}
|
||||
replicas: {{ .Values.config.cluster_size }}
|
||||
podManagementPolicy: {{ .Values.podManagementPolicy }}
|
||||
updateStrategy:
|
||||
type: {{ .Values.updateStrategy.type }}
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: {{ template "cassandra.name" . }}
|
||||
release: {{ .Release.Name }}
|
||||
{{- if .Values.podLabels }}
|
||||
{{ toYaml .Values.podLabels | indent 8 }}
|
||||
{{- end }}
|
||||
{{- if .Values.podAnnotations }}
|
||||
annotations:
|
||||
{{ toYaml .Values.podAnnotations | indent 8 }}
|
||||
{{- end }}
|
||||
spec:
|
||||
{{- if .Values.schedulerName }}
|
||||
schedulerName: "{{ .Values.schedulerName }}"
|
||||
{{- end }}
|
||||
hostNetwork: {{ .Values.hostNetwork }}
|
||||
{{- if .Values.selector }}
|
||||
{{ toYaml .Values.selector | indent 6 }}
|
||||
{{- end }}
|
||||
{{- if .Values.securityContext.enabled }}
|
||||
securityContext:
|
||||
fsGroup: {{ .Values.securityContext.fsGroup }}
|
||||
runAsUser: {{ .Values.securityContext.runAsUser }}
|
||||
{{- end }}
|
||||
{{- if .Values.affinity }}
|
||||
affinity:
|
||||
{{ toYaml .Values.affinity | indent 8 }}
|
||||
{{- end }}
|
||||
{{- if .Values.tolerations }}
|
||||
tolerations:
|
||||
{{ toYaml .Values.tolerations | indent 8 }}
|
||||
{{- end }}
|
||||
{{- if .Values.configOverrides }}
|
||||
initContainers:
|
||||
- name: config-copier
|
||||
image: busybox
|
||||
command: [ 'sh', '-c', 'cp /configmap-files/* /cassandra-configs/ && chown 999:999 /cassandra-configs/*']
|
||||
volumeMounts:
|
||||
{{- range $key, $value := .Values.configOverrides }}
|
||||
- name: cassandra-config-{{ $key | replace "." "-" | replace "_" "--" }}
|
||||
mountPath: /configmap-files/{{ $key }}
|
||||
subPath: {{ $key }}
|
||||
{{- end }}
|
||||
- name: cassandra-configs
|
||||
mountPath: /cassandra-configs/
|
||||
{{- end }}
|
||||
containers:
|
||||
{{- if .Values.extraContainers }}
|
||||
{{ tpl (toYaml .Values.extraContainers) . | indent 6}}
|
||||
{{- end }}
|
||||
{{- if .Values.exporter.enabled }}
|
||||
- name: cassandra-exporter
|
||||
image: "{{ .Values.exporter.image.repo }}:{{ .Values.exporter.image.tag }}"
|
||||
resources:
|
||||
{{ toYaml .Values.exporter.resources | indent 10 }}
|
||||
env:
|
||||
- name: CASSANDRA_EXPORTER_CONFIG_listenPort
|
||||
value: {{ .Values.exporter.port | quote }}
|
||||
- name: JVM_OPTS
|
||||
value: {{ .Values.exporter.jvmOpts | quote }}
|
||||
ports:
|
||||
- name: metrics
|
||||
containerPort: {{ .Values.exporter.port }}
|
||||
protocol: TCP
|
||||
- name: jmx
|
||||
containerPort: 5555
|
||||
livenessProbe:
|
||||
tcpSocket:
|
||||
port: {{ .Values.exporter.port }}
|
||||
readinessProbe:
|
||||
httpGet:
|
||||
path: /metrics
|
||||
port: {{ .Values.exporter.port }}
|
||||
initialDelaySeconds: 20
|
||||
timeoutSeconds: 45
|
||||
{{- end }}
|
||||
- name: {{ template "cassandra.fullname" . }}
|
||||
image: "{{ .Values.image.repo }}:{{ .Values.image.tag }}"
|
||||
imagePullPolicy: {{ .Values.image.pullPolicy | quote }}
|
||||
{{- if .Values.commandOverrides }}
|
||||
command: {{ .Values.commandOverrides }}
|
||||
{{- end }}
|
||||
{{- if .Values.argsOverrides }}
|
||||
args: {{ .Values.argsOverrides }}
|
||||
{{- end }}
|
||||
resources:
|
||||
{{ toYaml .Values.resources | indent 10 }}
|
||||
env:
|
||||
{{- $seed_size := default 1 .Values.config.seed_size | int -}}
|
||||
{{- $global := . }}
|
||||
- name: CASSANDRA_SEEDS
|
||||
{{- if .Values.hostNetwork }}
|
||||
value: {{ required "You must fill \".Values.config.seeds\" with list of Cassandra seeds when hostNetwork is set to true" .Values.config.seeds | quote }}
|
||||
{{- else }}
|
||||
value: "{{- range $i, $e := until $seed_size }}{{ template "cassandra.fullname" $global }}-{{ $i }}.{{ template "cassandra.fullname" $global }}.{{ $global.Release.Namespace }}.svc.{{ $global.Values.config.cluster_domain }}{{- if (lt ( add1 $i ) $seed_size ) }},{{- end }}{{- end }}"
|
||||
{{- end }}
|
||||
- name: MAX_HEAP_SIZE
|
||||
value: {{ default "8192M" .Values.config.max_heap_size | quote }}
|
||||
- name: HEAP_NEWSIZE
|
||||
value: {{ default "200M" .Values.config.heap_new_size | quote }}
|
||||
- name: CASSANDRA_ENDPOINT_SNITCH
|
||||
value: {{ default "SimpleSnitch" .Values.config.endpoint_snitch | quote }}
|
||||
- name: CASSANDRA_CLUSTER_NAME
|
||||
value: {{ default "Cassandra" .Values.config.cluster_name | quote }}
|
||||
- name: CASSANDRA_DC
|
||||
value: {{ default "DC1" .Values.config.dc_name | quote }}
|
||||
- name: CASSANDRA_RACK
|
||||
value: {{ default "RAC1" .Values.config.rack_name | quote }}
|
||||
- name: CASSANDRA_START_RPC
|
||||
value: {{ default "false" .Values.config.start_rpc | quote }}
|
||||
- name: POD_IP
|
||||
valueFrom:
|
||||
fieldRef:
|
||||
fieldPath: status.podIP
|
||||
{{- range $key, $value := .Values.env }}
|
||||
- name: {{ $key | quote }}
|
||||
value: {{ $value | quote }}
|
||||
{{- end }}
|
||||
livenessProbe:
|
||||
exec:
|
||||
command: [ "/bin/sh", "-c", "nodetool status" ]
|
||||
initialDelaySeconds: {{ .Values.livenessProbe.initialDelaySeconds }}
|
||||
periodSeconds: {{ .Values.livenessProbe.periodSeconds }}
|
||||
timeoutSeconds: {{ .Values.livenessProbe.timeoutSeconds }}
|
||||
successThreshold: {{ .Values.livenessProbe.successThreshold }}
|
||||
failureThreshold: {{ .Values.livenessProbe.failureThreshold }}
|
||||
readinessProbe:
|
||||
exec:
|
||||
command: [ "/bin/sh", "-c", "nodetool status | grep -E \"^UN\\s+{{ .Values.readinessProbe.address }}\"" ]
|
||||
initialDelaySeconds: {{ .Values.readinessProbe.initialDelaySeconds }}
|
||||
periodSeconds: {{ .Values.readinessProbe.periodSeconds }}
|
||||
timeoutSeconds: {{ .Values.readinessProbe.timeoutSeconds }}
|
||||
successThreshold: {{ .Values.readinessProbe.successThreshold }}
|
||||
failureThreshold: {{ .Values.readinessProbe.failureThreshold }}
|
||||
ports:
|
||||
- name: intra
|
||||
containerPort: 7000
|
||||
- name: tls
|
||||
containerPort: 7001
|
||||
- name: jmx
|
||||
containerPort: 7199
|
||||
- name: cql
|
||||
containerPort: {{ default 9042 .Values.config.ports.cql }}
|
||||
- name: thrift
|
||||
containerPort: {{ default 9160 .Values.config.ports.thrift }}
|
||||
{{- if .Values.config.ports.agent }}
|
||||
- name: agent
|
||||
containerPort: {{ .Values.config.ports.agent }}
|
||||
{{- end }}
|
||||
volumeMounts:
|
||||
- name: data
|
||||
mountPath: /var/lib/cassandra
|
||||
{{- if .Values.configOverrides }}
|
||||
- name: cassandra-configs
|
||||
mountPath: /etc/cassandra
|
||||
{{- end }}
|
||||
{{- if .Values.extraVolumeMounts }}
|
||||
{{ toYaml .Values.extraVolumeMounts | indent 8 }}
|
||||
{{- end }}
|
||||
{{- if not .Values.persistence.enabled }}
|
||||
lifecycle:
|
||||
preStop:
|
||||
exec:
|
||||
command: ["/bin/sh", "-c", "exec nodetool decommission"]
|
||||
{{- end }}
|
||||
terminationGracePeriodSeconds: {{ default 30 .Values.podSettings.terminationGracePeriodSeconds }}
|
||||
{{- if .Values.image.pullSecrets }}
|
||||
imagePullSecrets:
|
||||
- name: {{ .Values.image.pullSecrets }}
|
||||
{{- end }}
|
||||
{{- if or .Values.extraVolumes ( or .Values.configOverrides (not .Values.persistence.enabled) ) }}
|
||||
volumes:
|
||||
{{- end }}
|
||||
{{- if .Values.extraVolumes }}
|
||||
{{ toYaml .Values.extraVolumes | indent 6 }}
|
||||
{{- end }}
|
||||
{{- range $key, $value := .Values.configOverrides }}
|
||||
- configMap:
|
||||
name: cassandra
|
||||
name: cassandra-config-{{ $key | replace "." "-" | replace "_" "--" }}
|
||||
{{- end }}
|
||||
{{- if .Values.configOverrides }}
|
||||
- name: cassandra-configs
|
||||
emptyDir: {}
|
||||
{{- end }}
|
||||
{{- if not .Values.persistence.enabled }}
|
||||
- name: data
|
||||
emptyDir: {}
|
||||
{{- else }}
|
||||
volumeClaimTemplates:
|
||||
- metadata:
|
||||
name: data
|
||||
labels:
|
||||
app: {{ template "cassandra.name" . }}
|
||||
release: {{ .Release.Name }}
|
||||
spec:
|
||||
accessModes:
|
||||
- {{ .Values.persistence.accessMode | quote }}
|
||||
resources:
|
||||
requests:
|
||||
storage: {{ .Values.persistence.size | quote }}
|
||||
{{- if .Values.persistence.storageClass }}
|
||||
{{- if (eq "-" .Values.persistence.storageClass) }}
|
||||
storageClassName: ""
|
||||
{{- else }}
|
||||
storageClassName: "{{ .Values.persistence.storageClass }}"
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
|
|
@ -1,254 +0,0 @@
|
|||
## Cassandra image version
|
||||
## ref: https://hub.docker.com/r/library/cassandra/
|
||||
image:
|
||||
repo: cassandra
|
||||
tag: 3.11.6
|
||||
pullPolicy: IfNotPresent
|
||||
## Specify ImagePullSecrets for Pods
|
||||
## ref: https://kubernetes.io/docs/concepts/containers/images/#specifying-imagepullsecrets-on-a-pod
|
||||
# pullSecrets: myregistrykey
|
||||
|
||||
## Specify a service type
|
||||
## ref: http://kubernetes.io/docs/user-guide/services/
|
||||
service:
|
||||
type: ClusterIP
|
||||
annotations: ""
|
||||
|
||||
## Use an alternate scheduler, e.g. "stork".
|
||||
## ref: https://kubernetes.io/docs/tasks/administer-cluster/configure-multiple-schedulers/
|
||||
##
|
||||
# schedulerName:
|
||||
|
||||
## Persist data to a persistent volume
|
||||
persistence:
|
||||
enabled: true
|
||||
## cassandra data Persistent Volume Storage Class
|
||||
## If defined, storageClassName: <storageClass>
|
||||
## If set to "-", storageClassName: "", which disables dynamic provisioning
|
||||
## If undefined (the default) or set to null, no storageClassName spec is
|
||||
## set, choosing the default provisioner. (gp2 on AWS, standard on
|
||||
## GKE, AWS & OpenStack)
|
||||
##
|
||||
# storageClass: "-"
|
||||
accessMode: ReadWriteOnce
|
||||
size: 10Gi
|
||||
|
||||
## Configure resource requests and limits
|
||||
## ref: http://kubernetes.io/docs/user-guide/compute-resources/
|
||||
## Minimum memory for development is 4GB and 2 CPU cores
|
||||
## Minimum memory for production is 8GB and 4 CPU cores
|
||||
## ref: http://docs.datastax.com/en/archived/cassandra/2.0/cassandra/architecture/architecturePlanningHardware_c.html
|
||||
resources: {}
|
||||
# requests:
|
||||
# memory: 4Gi
|
||||
# cpu: 2
|
||||
# limits:
|
||||
# memory: 4Gi
|
||||
# cpu: 2
|
||||
|
||||
## Change cassandra configuration parameters below:
|
||||
## ref: http://docs.datastax.com/en/cassandra/3.0/cassandra/configuration/configCassandra_yaml.html
|
||||
## Recommended max heap size is 1/2 of system memory
|
||||
## Recommended heap new size is 1/4 of max heap size
|
||||
## ref: http://docs.datastax.com/en/cassandra/3.0/cassandra/operations/opsTuneJVM.html
|
||||
config:
|
||||
cluster_domain: cluster.local
|
||||
cluster_name: cassandra
|
||||
cluster_size: 3
|
||||
seed_size: 2
|
||||
num_tokens: 256
|
||||
# If you want Cassandra to use this datacenter and rack name,
|
||||
# you need to set endpoint_snitch to GossipingPropertyFileSnitch.
|
||||
# Otherwise, these values are ignored and datacenter1 and rack1
|
||||
# are used.
|
||||
dc_name: DC1
|
||||
rack_name: RAC1
|
||||
endpoint_snitch: SimpleSnitch
|
||||
max_heap_size: 2048M
|
||||
heap_new_size: 512M
|
||||
start_rpc: false
|
||||
ports:
|
||||
cql: 9042
|
||||
thrift: 9160
|
||||
# If a JVM Agent is in place
|
||||
# agent: 61621
|
||||
|
||||
## Cassandra config files overrides
|
||||
configOverrides: {}
|
||||
|
||||
## Cassandra docker command overrides
|
||||
commandOverrides: []
|
||||
|
||||
## Cassandra docker args overrides
|
||||
argsOverrides: []
|
||||
|
||||
## Custom env variables.
|
||||
## ref: https://hub.docker.com/_/cassandra/
|
||||
env: {}
|
||||
|
||||
## Liveness and Readiness probe values.
|
||||
## ref: https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-probes/
|
||||
livenessProbe:
|
||||
initialDelaySeconds: 90
|
||||
periodSeconds: 30
|
||||
timeoutSeconds: 5
|
||||
successThreshold: 1
|
||||
failureThreshold: 3
|
||||
readinessProbe:
|
||||
initialDelaySeconds: 90
|
||||
periodSeconds: 30
|
||||
timeoutSeconds: 5
|
||||
successThreshold: 1
|
||||
failureThreshold: 3
|
||||
address: "${POD_IP}"
|
||||
|
||||
## Configure node selector. Edit code below for adding selector to pods
|
||||
## ref: https://kubernetes.io/docs/user-guide/node-selection/
|
||||
# selector:
|
||||
# nodeSelector:
|
||||
# cloud.google.com/gke-nodepool: pool-db
|
||||
|
||||
## Additional pod annotations
|
||||
## ref: https://kubernetes.io/docs/concepts/overview/working-with-objects/annotations/
|
||||
podAnnotations: {}
|
||||
|
||||
## Additional pod labels
|
||||
## ref: https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/
|
||||
podLabels: {}
|
||||
|
||||
## Additional pod-level settings
|
||||
podSettings:
|
||||
# Change this to give pods more time to properly leave the cluster when not using persistent storage.
|
||||
terminationGracePeriodSeconds: 30
|
||||
|
||||
## Pod distruption budget
|
||||
podDisruptionBudget: {}
|
||||
# maxUnavailable: 1
|
||||
# minAvailable: 2
|
||||
|
||||
podManagementPolicy: OrderedReady
|
||||
updateStrategy:
|
||||
type: OnDelete
|
||||
|
||||
## Pod Security Context
|
||||
securityContext:
|
||||
enabled: false
|
||||
fsGroup: 999
|
||||
runAsUser: 999
|
||||
|
||||
## Affinity for pod assignment
|
||||
## Ref: https://kubernetes.io/docs/concepts/configuration/assign-pod-node/#affinity-and-anti-affinity
|
||||
affinity: {}
|
||||
|
||||
## Node tolerations for pod assignment
|
||||
## Ref: https://kubernetes.io/docs/concepts/configuration/taint-and-toleration/
|
||||
tolerations: []
|
||||
|
||||
rbac:
|
||||
# Specifies whether RBAC resources should be created
|
||||
create: true
|
||||
|
||||
serviceAccount:
|
||||
# Specifies whether a ServiceAccount should be created
|
||||
create: true
|
||||
# The name of the ServiceAccount to use.
|
||||
# If not set and create is true, a name is generated using the fullname template
|
||||
# name:
|
||||
|
||||
# Use host network for Cassandra pods
|
||||
# You must pass seed list into config.seeds property if set to true
|
||||
hostNetwork: false
|
||||
|
||||
## Backup cronjob configuration
|
||||
## Ref: https://github.com/maorfr/cain
|
||||
backup:
|
||||
enabled: false
|
||||
|
||||
# Schedule to run jobs. Must be in cron time format
|
||||
# Ref: https://crontab.guru/
|
||||
schedule:
|
||||
- keyspace: keyspace1
|
||||
cron: "0 7 * * *"
|
||||
- keyspace: keyspace2
|
||||
cron: "30 7 * * *"
|
||||
|
||||
annotations:
|
||||
# Example for authorization to AWS S3 using kube2iam
|
||||
# Can also be done using environment variables
|
||||
iam.amazonaws.com/role: cain
|
||||
|
||||
image:
|
||||
repository: maorfr/cain
|
||||
tag: 0.6.0
|
||||
|
||||
# Additional arguments for cain
|
||||
# Ref: https://github.com/maorfr/cain#usage
|
||||
extraArgs: []
|
||||
|
||||
# Add additional environment variables
|
||||
env:
|
||||
# Example environment variable required for AWS credentials chain
|
||||
- name: AWS_REGION
|
||||
value: us-east-1
|
||||
|
||||
resources:
|
||||
requests:
|
||||
memory: 1Gi
|
||||
cpu: 1
|
||||
limits:
|
||||
memory: 1Gi
|
||||
cpu: 1
|
||||
|
||||
# Name of the secret containing the credentials of the service account used by GOOGLE_APPLICATION_CREDENTIALS, as a credentials.json file
|
||||
# google:
|
||||
# serviceAccountSecret:
|
||||
|
||||
# Destination to store the backup artifacts
|
||||
# Supported cloud storage services: AWS S3, Minio S3, Azure Blob Storage, Google Cloud Storage
|
||||
# Additional support can added. Visit this repository for details
|
||||
# Ref: https://github.com/maorfr/skbn
|
||||
destination: s3://bucket/cassandra
|
||||
|
||||
## Cassandra exported configuration
|
||||
## ref: https://github.com/criteo/cassandra_exporter
|
||||
exporter:
|
||||
enabled: false
|
||||
serviceMonitor:
|
||||
enabled: false
|
||||
additionalLabels: {}
|
||||
# prometheus: default
|
||||
image:
|
||||
repo: criteord/cassandra_exporter
|
||||
tag: 2.0.2
|
||||
port: 5556
|
||||
jvmOpts: ""
|
||||
resources: {}
|
||||
# limits:
|
||||
# cpu: 1
|
||||
# memory: 1Gi
|
||||
# requests:
|
||||
# cpu: 1
|
||||
# memory: 1Gi
|
||||
|
||||
extraVolumes: []
|
||||
extraVolumeMounts: []
|
||||
# extraVolumes and extraVolumeMounts allows you to mount other volumes
|
||||
# Example Use Case: mount ssl certificates
|
||||
# extraVolumes:
|
||||
# - name: cas-certs
|
||||
# secret:
|
||||
# defaultMode: 420
|
||||
# secretName: cas-certs
|
||||
# extraVolumeMounts:
|
||||
# - name: cas-certs
|
||||
# mountPath: /certs
|
||||
# readOnly: true
|
||||
|
||||
extraContainers: []
|
||||
## Additional containers to be added
|
||||
# extraContainers:
|
||||
# - name: cassandra-sidecar
|
||||
# image: cassandra-sidecar:latest
|
||||
# volumeMounts:
|
||||
# - name: some-mount
|
||||
# mountPath: /some/path
|
||||
Binary file not shown.
|
|
@ -1,2 +0,0 @@
|
|||
tests/
|
||||
.pytest_cache/
|
||||
|
|
@ -1,12 +0,0 @@
|
|||
apiVersion: v1
|
||||
appVersion: 7.8.1
|
||||
description: Official Elastic helm chart for Elasticsearch
|
||||
home: https://github.com/elastic/helm-charts
|
||||
icon: https://helm.elastic.co/icons/elasticsearch.png
|
||||
maintainers:
|
||||
- email: helm-charts@elastic.co
|
||||
name: Elastic
|
||||
name: elasticsearch
|
||||
sources:
|
||||
- https://github.com/elastic/elasticsearch
|
||||
version: 7.8.1
|
||||
|
|
@ -1 +0,0 @@
|
|||
include ../helpers/common.mk
|
||||
|
|
@ -1,445 +0,0 @@
|
|||
# Elasticsearch Helm Chart
|
||||
|
||||
This Helm chart is a lightweight way to configure and run our official
|
||||
[Elasticsearch Docker image][].
|
||||
|
||||
|
||||
<!-- START doctoc generated TOC please keep comment here to allow auto update -->
|
||||
<!-- DON'T EDIT THIS SECTION, INSTEAD RE-RUN doctoc TO UPDATE -->
|
||||
|
||||
|
||||
- [Requirements](#requirements)
|
||||
- [Installing](#installing)
|
||||
- [Upgrading](#upgrading)
|
||||
- [Usage notes](#usage-notes)
|
||||
- [Configuration](#configuration)
|
||||
- [Deprecated](#deprecated)
|
||||
- [FAQ](#faq)
|
||||
- [How to deploy this chart on a specific K8S distribution?](#how-to-deploy-this-chart-on-a-specific-k8s-distribution)
|
||||
- [How to deploy dedicated nodes types?](#how-to-deploy-dedicated-nodes-types)
|
||||
- [Clustering and Node Discovery](#clustering-and-node-discovery)
|
||||
- [How to deploy clusters with security (authentication and TLS) enabled?](#how-to-deploy-clusters-with-security-authentication-and-tls-enabled)
|
||||
- [How to migrate from helm/charts stable chart?](#how-to-migrate-from-helmcharts-stable-chart)
|
||||
- [How to install OSS version of Elasticsearch?](#how-to-install-oss-version-of-elasticsearch)
|
||||
- [How to install plugins?](#how-to-install-plugins)
|
||||
- [How to use the keystore?](#how-to-use-the-keystore)
|
||||
- [Basic example](#basic-example)
|
||||
- [Multiple keys](#multiple-keys)
|
||||
- [Custom paths and keys](#custom-paths-and-keys)
|
||||
- [How to enable snapshotting?](#how-to-enable-snapshotting)
|
||||
- [How to configure templates post-deployment?](#how-to-configure-templates-post-deployment)
|
||||
- [Contributing](#contributing)
|
||||
|
||||
<!-- END doctoc generated TOC please keep comment here to allow auto update -->
|
||||
<!-- Use this to update TOC: -->
|
||||
<!-- docker run --rm -it -v $(pwd):/usr/src jorgeandrada/doctoc --github -->
|
||||
|
||||
|
||||
## Requirements
|
||||
|
||||
* [Helm][] >=2.8.0 and <3.0.0
|
||||
* Kubernetes >=1.8
|
||||
* Minimum cluster requirements include the following to run this chart with
|
||||
default settings. All of these settings are configurable.
|
||||
* Three Kubernetes nodes to respect the default "hard" affinity settings
|
||||
* 1GB of RAM for the JVM heap
|
||||
|
||||
See [supported configurations][] for more details.
|
||||
|
||||
|
||||
## Installing
|
||||
|
||||
This chart is tested with 7.8.1 version.
|
||||
|
||||
* Add the Elastic Helm charts repo:
|
||||
`helm repo add elastic https://helm.elastic.co`
|
||||
|
||||
* Install 7.8.1 release:
|
||||
`helm install --name elasticsearch --version 7.8.1 elastic/elasticsearch`
|
||||
|
||||
|
||||
## Upgrading
|
||||
|
||||
Please always check [CHANGELOG.md][] and [BREAKING_CHANGES.md][] before
|
||||
upgrading to a new chart version.
|
||||
|
||||
|
||||
## Usage notes
|
||||
|
||||
* This repo includes a number of [examples][] configurations which can be used
|
||||
as a reference. They are also used in the automated testing of this chart.
|
||||
* Automated testing of this chart is currently only run against GKE (Google
|
||||
Kubernetes Engine).
|
||||
* The chart deploys a StatefulSet and by default will do an automated rolling
|
||||
update of your cluster. It does this by waiting for the cluster health to become
|
||||
green after each instance is updated. If you prefer to update manually you can
|
||||
set `OnDelete` [updateStrategy][].
|
||||
* It is important to verify that the JVM heap size in `esJavaOpts` and to set
|
||||
the CPU/Memory `resources` to something suitable for your cluster.
|
||||
* To simplify chart and maintenance each set of node groups is deployed as a
|
||||
separate Helm release. Take a look at the [multi][] example to get an idea for
|
||||
how this works. Without doing this it isn't possible to resize persistent
|
||||
volumes in a StatefulSet. By setting it up this way it makes it possible to add
|
||||
more nodes with a new storage size then drain the old ones. It also solves the
|
||||
problem of allowing the user to determine which node groups to update first when
|
||||
doing upgrades or changes.
|
||||
* We have designed this chart to be very un-opinionated about how to configure
|
||||
Elasticsearch. It exposes ways to set environment variables and mount secrets
|
||||
inside of the container. Doing this makes it much easier for this chart to
|
||||
support multiple versions with minimal changes.
|
||||
|
||||
|
||||
## Configuration
|
||||
|
||||
| Parameter | Description | Default |
|
||||
|------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------|
|
||||
| `antiAffinityTopologyKey` | The [anti-affinity][] topology key. By default this will prevent multiple Elasticsearch nodes from running on the same Kubernetes node | `kubernetes.io/hostname` |
|
||||
| `antiAffinity` | Setting this to hard enforces the [anti-affinity][] rules. If it is set to soft it will be done "best effort". Other values will be ignored | `hard` |
|
||||
| `clusterHealthCheckParams` | The [Elasticsearch cluster health status params][] that will be used by readiness [probe][] command | `wait_for_status=green&timeout=1s` |
|
||||
| `clusterName` | This will be used as the Elasticsearch [cluster.name][] and should be unique per cluster in the namespace | `elasticsearch` |
|
||||
| `enableServiceLinks` | Set to false to disabling service links, which can cause slow pod startup times when there are many services in the current namespace. | `true` |
|
||||
| `envFrom` | Templatable string to be passed to the [environment from variables][] which will be appended to the `envFrom:` definition for the container | `[]` |
|
||||
| `esConfig` | Allows you to add any config files in `/usr/share/elasticsearch/config/` such as `elasticsearch.yml` and `log4j2.properties`. See [values.yaml][] for an example of the formatting | `{}` |
|
||||
| `esJavaOpts` | [Java options][] for Elasticsearch. This is where you should configure the [jvm heap size][] | `-Xmx1g -Xms1g` |
|
||||
| `esMajorVersion` | Used to set major version specific configuration. If you are using a custom image and not running the default Elasticsearch version you will need to set this to the version you are running (e.g. `esMajorVersion: 6`) | `""` |
|
||||
| `extraContainers` | Templatable string of additional `containers` to be passed to the `tpl` function | `""` |
|
||||
| `extraEnvs` | Extra [environment variables][] which will be appended to the `env:` definition for the container | `[]` |
|
||||
| `extraInitContainers` | Templatable string of additional `initContainers` to be passed to the `tpl` function | `""` |
|
||||
| `extraVolumeMounts` | Templatable string of additional `volumeMounts` to be passed to the `tpl` function | `""` |
|
||||
| `extraVolumes` | Templatable string of additional `volumes` to be passed to the `tpl` function | `""` |
|
||||
| `fullnameOverride` | Overrides the `clusterName` and `nodeGroup` when used in the naming of resources. This should only be used when using a single `nodeGroup`, otherwise you will have name conflicts | `""` |
|
||||
| `httpPort` | The http port that Kubernetes will use for the healthchecks and the service. If you change this you will also need to set [http.port][] in `extraEnvs` | `9200` |
|
||||
| `imagePullPolicy` | The Kubernetes [imagePullPolicy][] value | `IfNotPresent` |
|
||||
| `imagePullSecrets` | Configuration for [imagePullSecrets][] so that you can use a private registry for your image | `[]` |
|
||||
| `imageTag` | The Elasticsearch Docker image tag | `7.8.1` |
|
||||
| `image` | The Elasticsearch Docker image | `docker.elastic.co/elasticsearch/elasticsearch` |
|
||||
| `ingress` | Configurable [ingress][] to expose the Elasticsearch service. See [values.yaml][] for an example | see [values.yaml][] |
|
||||
| `initResources` | Allows you to set the [resources][] for the `initContainer` in the StatefulSet | `{}` |
|
||||
| `keystore` | Allows you map Kubernetes secrets into the keystore. See the [config example][] and [how to use the keystore][] | `[]` |
|
||||
| `labels` | Configurable [labels][] applied to all Elasticsearch pods | `{}` |
|
||||
| `lifecycle` | Allows you to add [lifecycle hooks][]. See [values.yaml][] for an example of the formatting | `{}` |
|
||||
| `masterService` | The service name used to connect to the masters. You only need to set this if your master `nodeGroup` is set to something other than `master`. See [Clustering and Node Discovery][] for more information | `""` |
|
||||
| `masterTerminationFix` | A workaround needed for Elasticsearch < 7.2 to prevent master status being lost during restarts [#63][] | `false` |
|
||||
| `maxUnavailable` | The [maxUnavailable][] value for the pod disruption budget. By default this will prevent Kubernetes from having more than 1 unhealthy pod in the node group | `1` |
|
||||
| `minimumMasterNodes` | The value for [discovery.zen.minimum_master_nodes][]. Should be set to `(master_eligible_nodes / 2) + 1`. Ignored in Elasticsearch versions >= 7 | `2` |
|
||||
| `nameOverride` | Overrides the `clusterName` when used in the naming of resources | `""` |
|
||||
| `networkHost` | Value for the [network.host Elasticsearch setting][] | `0.0.0.0` |
|
||||
| `nodeAffinity` | Value for the [node affinity settings][] | `{}` |
|
||||
| `nodeGroup` | This is the name that will be used for each group of nodes in the cluster. The name will be `clusterName-nodeGroup-X` , `nameOverride-nodeGroup-X` if a `nameOverride` is specified, and `fullnameOverride-X` if a `fullnameOverride` is specified | `master` |
|
||||
| `nodeSelector` | Configurable [nodeSelector][] so that you can target specific nodes for your Elasticsearch cluster | `{}` |
|
||||
| `persistence` | Enables a persistent volume for Elasticsearch data. Can be disabled for nodes that only have [roles][] which don't require persistent data | see [values.yaml][] |
|
||||
| `podAnnotations` | Configurable [annotations][] applied to all Elasticsearch pods | `{}` |
|
||||
| `podManagementPolicy` | By default Kubernetes [deploys StatefulSets serially][]. This deploys them in parallel so that they can discover each other | `Parallel` |
|
||||
| `podSecurityContext` | Allows you to set the [securityContext][] for the pod | see [values.yaml][] |
|
||||
| `podSecurityPolicy` | Configuration for create a pod security policy with minimal permissions to run this Helm chart with `create: true`. Also can be used to reference an external pod security policy with `name: "externalPodSecurityPolicy"` | see [values.yaml][] |
|
||||
| `priorityClassName` | The name of the [PriorityClass][]. No default is supplied as the PriorityClass must be created first | `""` |
|
||||
| `protocol` | The protocol that will be used for the readiness [probe][]. Change this to `https` if you have `xpack.security.http.ssl.enabled` set | `http` |
|
||||
| `rbac` | Configuration for creating a role, role binding and ServiceAccount as part of this Helm chart with `create: true`. Also can be used to reference an external ServiceAccount with `serviceAccountName: "externalServiceAccountName"` | see [values.yaml][] |
|
||||
| `readinessProbe` | Configuration fields for the readiness [probe][] | see [values.yaml][] |
|
||||
| `replicas` | Kubernetes replica count for the StatefulSet (i.e. how many pods) | `3` |
|
||||
| `resources` | Allows you to set the [resources][] for the StatefulSet | see [values.yaml][] |
|
||||
| `roles` | A hash map with the specific [roles][] for the `nodeGroup` | see [values.yaml][] |
|
||||
| `schedulerName` | Name of the [alternate scheduler][] | `""` |
|
||||
| `secretMounts` | Allows you easily mount a secret as a file inside the StatefulSet. Useful for mounting certificates and other secrets. See [values.yaml][] for an example | `[]` |
|
||||
| `securityContext` | Allows you to set the [securityContext][] for the container | see [values.yaml][] |
|
||||
| `service.annotations` | [LoadBalancer annotations][] that Kubernetes will use for the service. This will configure load balancer if `service.type` is `LoadBalancer` | `{}` |
|
||||
| `service.httpPortName` | The name of the http port within the service | `http` |
|
||||
| `service.labelsHeadless` | Labels to be added to headless service | `{}` |
|
||||
| `service.labels` | Labels to be added to non-headless service | `{}` |
|
||||
| `service.loadBalancerIP` | Some cloud providers allow you to specify the [loadBalancer][] IP. If the `loadBalancerIP` field is not specified, the IP is dynamically assigned. If you specify a `loadBalancerIP` but your cloud provider does not support the feature, it is ignored. | `""` |
|
||||
| `service.loadBalancerSourceRanges` | The IP ranges that are allowed to access | `[]` |
|
||||
| `service.nodePort` | Custom [nodePort][] port that can be set if you are using `service.type: nodePort` | `""` |
|
||||
| `service.transportPortName` | The name of the transport port within the service | `transport` |
|
||||
| `service.type` | Elasticsearch [Service Types][] | `ClusterIP` |
|
||||
| `sidecarResources` | Allows you to set the [resources][] for the sidecar containers in the StatefulSet | {} |
|
||||
| `sysctlInitContainer` | Allows you to disable the `sysctlInitContainer` if you are setting [sysctl vm.max_map_count][] with another method | `enabled: true` |
|
||||
| `sysctlVmMaxMapCount` | Sets the [sysctl vm.max_map_count][] needed for Elasticsearch | `262144` |
|
||||
| `terminationGracePeriod` | The [terminationGracePeriod][] in seconds used when trying to stop the pod | `120` |
|
||||
| `tolerations` | Configurable [tolerations][] | `[]` |
|
||||
| `transportPort` | The transport port that Kubernetes will use for the service. If you change this you will also need to set [transport port configuration][] in `extraEnvs` | `9300` |
|
||||
| `updateStrategy` | The [updateStrategy][] for the StatefulSet. By default Kubernetes will wait for the cluster to be green after upgrading each pod. Setting this to `OnDelete` will allow you to manually delete each pod during upgrades | `RollingUpdate` |
|
||||
| `volumeClaimTemplate` | Configuration for the [volumeClaimTemplate for StatefulSets][]. You will want to adjust the storage (default `30Gi` ) and the `storageClassName` if you are using a different storage class | see [values.yaml][] |
|
||||
|
||||
### Deprecated
|
||||
|
||||
| Parameter | Description | Default |
|
||||
|-----------|---------------------------------------------------------------------------------------------------------------|---------|
|
||||
| `fsGroup` | The Group ID (GID) for [securityContext][] so that the Elasticsearch user can read from the persistent volume | `""` |
|
||||
|
||||
|
||||
## FAQ
|
||||
|
||||
### How to deploy this chart on a specific K8S distribution?
|
||||
|
||||
This chart is designed to run on production scale Kubernetes clusters with
|
||||
multiple nodes, lots of memory and persistent storage. For that reason it can be
|
||||
a bit tricky to run them against local Kubernetes environments such as
|
||||
[Minikube][].
|
||||
|
||||
This chart is highly tested with [GKE][], but some K8S distribution also
|
||||
requires specific configurations.
|
||||
|
||||
We provide examples of configuration for the following K8S providers:
|
||||
|
||||
- [Docker for Mac][]
|
||||
- [KIND][]
|
||||
- [Minikube][]
|
||||
- [MicroK8S][]
|
||||
- [OpenShift][]
|
||||
|
||||
### How to deploy dedicated nodes types?
|
||||
|
||||
All the Elasticsearch pods deployed share the same configuration. If you need to
|
||||
deploy dedicated [nodes types][] (for example dedicated master and data nodes),
|
||||
you can deploy multiple releases of this chart with different configurations
|
||||
while they share the same `clusterName` value.
|
||||
|
||||
For each Helm release, the nodes types can then be defined using `roles` value.
|
||||
|
||||
An example of Elasticsearch cluster using 2 different Helm releases for master
|
||||
and data nodes can be found in [examples/multi][].
|
||||
|
||||
#### Clustering and Node Discovery
|
||||
|
||||
This chart facilitates Elasticsearch node discovery and services by creating two
|
||||
`Service` definitions in Kubernetes, one with the name `$clusterName-$nodeGroup`
|
||||
and another named `$clusterName-$nodeGroup-headless`.
|
||||
Only `Ready` pods are a part of the `$clusterName-$nodeGroup` service, while all
|
||||
pods ( `Ready` or not) are a part of `$clusterName-$nodeGroup-headless`.
|
||||
|
||||
If your group of master nodes has the default `nodeGroup: master` then you can
|
||||
just add new groups of nodes with a different `nodeGroup` and they will
|
||||
automatically discover the correct master. If your master nodes have a different
|
||||
`nodeGroup` name then you will need to set `masterService` to
|
||||
`$clusterName-$masterNodeGroup`.
|
||||
|
||||
The chart value for `masterService` is used to populate
|
||||
`discovery.zen.ping.unicast.hosts` , which Elasticsearch nodes will use to
|
||||
contact master nodes and form a cluster.
|
||||
Therefore, to add a group of nodes to an existing cluster, setting
|
||||
`masterService` to the desired `Service` name of the related cluster is
|
||||
sufficient.
|
||||
|
||||
### How to deploy clusters with security (authentication and TLS) enabled?
|
||||
|
||||
This Helm chart can use existing [Kubernetes secrets][] to setup
|
||||
credentials or certificates for examples. These secrets should be created
|
||||
outside of this chart and accessed using [environment variables][] and volumes.
|
||||
|
||||
An example of Elasticsearch cluster using security can be found in
|
||||
[examples/security][].
|
||||
|
||||
### How to migrate from helm/charts stable chart?
|
||||
|
||||
If you currently have a cluster deployed with the [helm/charts stable][] chart
|
||||
you can follow the [migration guide][].
|
||||
|
||||
### How to install OSS version of Elasticsearch?
|
||||
|
||||
Deploying OSS version of Elasticsearch can be done by setting `image` value to
|
||||
[Elasticsearch OSS Docker image][]
|
||||
|
||||
An example of Elasticsearch cluster using OSS version can be found in
|
||||
[examples/oss][].
|
||||
|
||||
### How to install plugins?
|
||||
|
||||
The recommended way to install plugins into our Docker images is to create a
|
||||
[custom Docker image][].
|
||||
|
||||
The Dockerfile would look something like:
|
||||
|
||||
```
|
||||
ARG elasticsearch_version
|
||||
FROM docker.elastic.co/elasticsearch/elasticsearch:${elasticsearch_version}
|
||||
|
||||
RUN bin/elasticsearch-plugin install --batch repository-gcs
|
||||
```
|
||||
|
||||
And then updating the `image` in values to point to your custom image.
|
||||
|
||||
There are a couple reasons we recommend this.
|
||||
|
||||
1. Tying the availability of Elasticsearch to the download service to install
|
||||
plugins is not a great idea or something that we recommend. Especially in
|
||||
Kubernetes where it is normal and expected for a container to be moved to
|
||||
another host at random times.
|
||||
2. Mutating the state of a running Docker image (by installing plugins) goes
|
||||
against best practices of containers and immutable infrastructure.
|
||||
|
||||
### How to use the keystore?
|
||||
|
||||
#### Basic example
|
||||
|
||||
Create the secret, the key name needs to be the keystore key path. In this
|
||||
example we will create a secret from a file and from a literal string.
|
||||
|
||||
```
|
||||
kubectl create secret generic encryption_key --from-file=xpack.watcher.encryption_key=./watcher_encryption_key
|
||||
kubectl create secret generic slack_hook --from-literal=xpack.notification.slack.account.monitoring.secure_url='https://hooks.slack.com/services/asdasdasd/asdasdas/asdasd'
|
||||
```
|
||||
|
||||
To add these secrets to the keystore:
|
||||
|
||||
```
|
||||
keystore:
|
||||
- secretName: encryption_key
|
||||
- secretName: slack_hook
|
||||
```
|
||||
|
||||
#### Multiple keys
|
||||
|
||||
All keys in the secret will be added to the keystore. To create the previous
|
||||
example in one secret you could also do:
|
||||
|
||||
```
|
||||
kubectl create secret generic keystore_secrets --from-file=xpack.watcher.encryption_key=./watcher_encryption_key --from-literal=xpack.notification.slack.account.monitoring.secure_url='https://hooks.slack.com/services/asdasdasd/asdasdas/asdasd'
|
||||
```
|
||||
|
||||
```
|
||||
keystore:
|
||||
- secretName: keystore_secrets
|
||||
```
|
||||
|
||||
#### Custom paths and keys
|
||||
|
||||
If you are using these secrets for other applications (besides the Elasticsearch
|
||||
keystore) then it is also possible to specify the keystore path and which keys
|
||||
you want to add. Everything specified under each `keystore` item will be passed
|
||||
through to the `volumeMounts` section for mounting the [secret][]. In this
|
||||
example we will only add the `slack_hook` key from a secret that also has other
|
||||
keys. Our secret looks like this:
|
||||
|
||||
```
|
||||
kubectl create secret generic slack_secrets --from-literal=slack_channel='#general' --from-literal=slack_hook='https://hooks.slack.com/services/asdasdasd/asdasdas/asdasd'
|
||||
```
|
||||
|
||||
We only want to add the `slack_hook` key to the keystore at path
|
||||
`xpack.notification.slack.account.monitoring.secure_url`:
|
||||
|
||||
```
|
||||
keystore:
|
||||
- secretName: slack_secrets
|
||||
items:
|
||||
- key: slack_hook
|
||||
path: xpack.notification.slack.account.monitoring.secure_url
|
||||
```
|
||||
|
||||
You can also take a look at the [config example][] which is used as part of the
|
||||
automated testing pipeline.
|
||||
|
||||
### How to enable snapshotting?
|
||||
|
||||
1. Install your [snapshot plugin][] into a custom Docker image following the
|
||||
[how to install plugins guide][].
|
||||
2. Add any required secrets or credentials into an Elasticsearch keystore
|
||||
following the [how to use the keystore][] guide.
|
||||
3. Configure the [snapshot repository][] as you normally would.
|
||||
4. To automate snapshots you can use a tool like [curator][]. In the future
|
||||
there are plans to have Elasticsearch manage automated snapshots with
|
||||
[Snapshot Lifecycle Management][].
|
||||
|
||||
### How to configure templates post-deployment?
|
||||
|
||||
You can use `postStart` [lifecycle hooks][] to run code triggered after a
|
||||
container is created.
|
||||
|
||||
Here is an example of `postStart` hook to configure templates:
|
||||
|
||||
```yaml
|
||||
lifecycle:
|
||||
postStart:
|
||||
exec:
|
||||
command:
|
||||
- bash
|
||||
- -c
|
||||
- |
|
||||
#!/bin/bash
|
||||
# Add a template to adjust number of shards/replicas
|
||||
TEMPLATE_NAME=my_template
|
||||
INDEX_PATTERN="logstash-*"
|
||||
SHARD_COUNT=8
|
||||
REPLICA_COUNT=1
|
||||
ES_URL=http://localhost:9200
|
||||
while [[ "$(curl -s -o /dev/null -w '%{http_code}\n' $ES_URL)" != "200" ]]; do sleep 1; done
|
||||
curl -XPUT "$ES_URL/_template/$TEMPLATE_NAME" -H 'Content-Type: application/json' -d'{"index_patterns":['\""$INDEX_PATTERN"\"'],"settings":{"number_of_shards":'$SHARD_COUNT',"number_of_replicas":'$REPLICA_COUNT'}}'
|
||||
```
|
||||
|
||||
|
||||
## Contributing
|
||||
|
||||
Please check [CONTRIBUTING.md][] before any contribution or for any questions
|
||||
about our development and testing process.
|
||||
|
||||
|
||||
[#63]: https://github.com/elastic/helm-charts/issues/63
|
||||
[BREAKING_CHANGES.md]: https://github.com/elastic/helm-charts/blob/master/BREAKING_CHANGES.md
|
||||
[CHANGELOG.md]: https://github.com/elastic/helm-charts/blob/master/CHANGELOG.md
|
||||
[CONTRIBUTING.md]: https://github.com/elastic/helm-charts/blob/master/CONTRIBUTING.md
|
||||
[alternate scheduler]: https://kubernetes.io/docs/tasks/administer-cluster/configure-multiple-schedulers/#specify-schedulers-for-pods
|
||||
[annotations]: https://kubernetes.io/docs/concepts/overview/working-with-objects/annotations/
|
||||
[anti-affinity]: https://kubernetes.io/docs/concepts/configuration/assign-pod-node/#affinity-and-anti-affinity
|
||||
[cluster.name]: https://www.elastic.co/guide/en/elasticsearch/reference/7.8/cluster.name.html
|
||||
[clustering and node discovery]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/README.md#clustering-and-node-discovery
|
||||
[config example]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/config/values.yaml
|
||||
[curator]: https://www.elastic.co/guide/en/elasticsearch/client/curator/7.8/snapshot.html
|
||||
[custom docker image]: https://www.elastic.co/guide/en/elasticsearch/reference/7.8/docker.html#_c_customized_image
|
||||
[deploys statefulsets serially]: https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/#pod-management-policies
|
||||
[discovery.zen.minimum_master_nodes]: https://www.elastic.co/guide/en/elasticsearch/reference/7.8/discovery-settings.html#minimum_master_nodes
|
||||
[docker for mac]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/docker-for-mac
|
||||
[elasticsearch cluster health status params]: https://www.elastic.co/guide/en/elasticsearch/reference/7.8/cluster-health.html#request-params
|
||||
[elasticsearch docker image]: https://www.elastic.co/guide/en/elasticsearch/reference/7.8/docker.html
|
||||
[elasticsearch oss docker image]: https://www.docker.elastic.co/r/elasticsearch/elasticsearch-oss
|
||||
[environment variables]: https://kubernetes.io/docs/tasks/inject-data-application/define-environment-variable-container/#using-environment-variables-inside-of-your-config
|
||||
[environment from variables]: https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/#configure-all-key-value-pairs-in-a-configmap-as-container-environment-variables
|
||||
[examples]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/
|
||||
[examples/multi]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/multi
|
||||
[examples/oss]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/oss
|
||||
[examples/security]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/security
|
||||
[gke]: https://cloud.google.com/kubernetes-engine
|
||||
[helm]: https://helm.sh
|
||||
[helm/charts stable]: https://github.com/helm/charts/tree/master/stable/elasticsearch/
|
||||
[how to install plugins guide]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/README.md#how-to-install-plugins
|
||||
[how to use the keystore]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/README.md#how-to-use-the-keystore
|
||||
[http.port]: https://www.elastic.co/guide/en/elasticsearch/reference/7.8/modules-http.html#_settings
|
||||
[imagePullPolicy]: https://kubernetes.io/docs/concepts/containers/images/#updating-images
|
||||
[imagePullSecrets]: https://kubernetes.io/docs/tasks/configure-pod-container/pull-image-private-registry/#create-a-pod-that-uses-your-secret
|
||||
[ingress]: https://kubernetes.io/docs/concepts/services-networking/ingress/
|
||||
[java options]: https://www.elastic.co/guide/en/elasticsearch/reference/7.8/jvm-options.html
|
||||
[jvm heap size]: https://www.elastic.co/guide/en/elasticsearch/reference/7.8/heap-size.html
|
||||
[kind]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/kubernetes-kind
|
||||
[kubernetes secrets]: https://kubernetes.io/docs/concepts/configuration/secret/
|
||||
[labels]: https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/
|
||||
[lifecycle hooks]: https://kubernetes.io/docs/concepts/containers/container-lifecycle-hooks/
|
||||
[loadBalancer annotations]: https://kubernetes.io/docs/concepts/services-networking/service/#ssl-support-on-aws
|
||||
[loadBalancer]: https://kubernetes.io/docs/concepts/services-networking/service/#loadbalancer
|
||||
[maxUnavailable]: https://kubernetes.io/docs/tasks/run-application/configure-pdb/#specifying-a-poddisruptionbudget
|
||||
[migration guide]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/migration/README.md
|
||||
[minikube]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/minikube
|
||||
[microk8s]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/microk8s
|
||||
[multi]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/multi/
|
||||
[network.host elasticsearch setting]: https://www.elastic.co/guide/en/elasticsearch/reference/7.8/network.host.html
|
||||
[node affinity settings]: https://kubernetes.io/docs/concepts/configuration/assign-pod-node/#node-affinity-beta-feature
|
||||
[node-certificates]: https://www.elastic.co/guide/en/elasticsearch/reference/7.8/configuring-tls.html#node-certificates
|
||||
[nodePort]: https://kubernetes.io/docs/concepts/services-networking/service/#nodeport
|
||||
[nodes types]: https://www.elastic.co/guide/en/elasticsearch/reference/7.8/modules-node.html
|
||||
[nodeSelector]: https://kubernetes.io/docs/concepts/configuration/assign-pod-node/#nodeselector
|
||||
[openshift]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/openshift
|
||||
[priorityClass]: https://kubernetes.io/docs/concepts/configuration/pod-priority-preemption/#priorityclass
|
||||
[probe]: https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-probes/
|
||||
[resources]: https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/
|
||||
[roles]: https://www.elastic.co/guide/en/elasticsearch/reference/7.8/modules-node.html
|
||||
[secret]: https://kubernetes.io/docs/concepts/configuration/secret/#using-secrets
|
||||
[securityContext]: https://kubernetes.io/docs/tasks/configure-pod-container/security-context/
|
||||
[service types]: https://kubernetes.io/docs/concepts/services-networking/service/#publishing-services-service-types
|
||||
[snapshot lifecycle management]: https://github.com/elastic/elasticsearch/issues/38461
|
||||
[snapshot plugin]: https://www.elastic.co/guide/en/elasticsearch/plugins/7.8/repository.html
|
||||
[snapshot repository]: https://www.elastic.co/guide/en/elasticsearch/reference/7.8/modules-snapshots.html
|
||||
[supported configurations]: https://github.com/elastic/helm-charts/tree/7.8/README.md#supported-configurations
|
||||
[sysctl vm.max_map_count]: https://www.elastic.co/guide/en/elasticsearch/reference/7.8/vm-max-map-count.html#vm-max-map-count
|
||||
[terminationGracePeriod]: https://kubernetes.io/docs/concepts/workloads/pods/pod/#termination-of-pods
|
||||
[tolerations]: https://kubernetes.io/docs/concepts/configuration/taint-and-toleration/
|
||||
[transport port configuration]: https://www.elastic.co/guide/en/elasticsearch/reference/7.8/modules-transport.html#_transport_settings
|
||||
[updateStrategy]: https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/
|
||||
[values.yaml]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/values.yaml
|
||||
[volumeClaimTemplate for statefulsets]: https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/#stable-storage
|
||||
|
|
@ -1,19 +0,0 @@
|
|||
default: test
|
||||
include ../../../helpers/examples.mk
|
||||
|
||||
RELEASE := helm-es-config
|
||||
|
||||
install:
|
||||
helm upgrade --wait --timeout=600 --install $(RELEASE) --values ./values.yaml ../../
|
||||
|
||||
secrets:
|
||||
kubectl delete secret elastic-config-credentials elastic-config-secret elastic-config-slack elastic-config-custom-path || true
|
||||
kubectl create secret generic elastic-config-credentials --from-literal=password=changeme --from-literal=username=elastic
|
||||
kubectl create secret generic elastic-config-slack --from-literal=xpack.notification.slack.account.monitoring.secure_url='https://hooks.slack.com/services/asdasdasd/asdasdas/asdasd'
|
||||
kubectl create secret generic elastic-config-secret --from-file=xpack.watcher.encryption_key=./watcher_encryption_key
|
||||
kubectl create secret generic elastic-config-custom-path --from-literal=slack_url='https://hooks.slack.com/services/asdasdasd/asdasdas/asdasd' --from-literal=thing_i_don_tcare_about=test
|
||||
|
||||
test: secrets install goss
|
||||
|
||||
purge:
|
||||
helm del --purge $(RELEASE)
|
||||
|
|
@ -1,27 +0,0 @@
|
|||
# Config
|
||||
|
||||
This example deploy a single node Elasticsearch 7.8.1 with authentication and
|
||||
custom [values][].
|
||||
|
||||
|
||||
## Usage
|
||||
|
||||
* Create the required secrets: `make secrets`
|
||||
|
||||
* Deploy Elasticsearch chart with the default values: `make install`
|
||||
|
||||
* You can now setup a port forward to query Elasticsearch API:
|
||||
|
||||
```
|
||||
kubectl port-forward svc/config-master 9200
|
||||
curl -u elastic:changeme http://localhost:9200/_cat/indices
|
||||
```
|
||||
|
||||
|
||||
## Testing
|
||||
|
||||
You can also run [goss integration tests][] using `make test`
|
||||
|
||||
|
||||
[goss integration tests]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/config/test/goss.yaml
|
||||
[values]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/config/values.yaml
|
||||
|
|
@ -1,26 +0,0 @@
|
|||
http:
|
||||
http://localhost:9200/_cluster/health:
|
||||
status: 200
|
||||
timeout: 2000
|
||||
body:
|
||||
- 'green'
|
||||
- '"number_of_nodes":1'
|
||||
- '"number_of_data_nodes":1'
|
||||
|
||||
http://localhost:9200:
|
||||
status: 200
|
||||
timeout: 2000
|
||||
body:
|
||||
- '"cluster_name" : "config"'
|
||||
- '"name" : "config-master-0"'
|
||||
- 'You Know, for Search'
|
||||
|
||||
command:
|
||||
"elasticsearch-keystore list":
|
||||
exit-status: 0
|
||||
stdout:
|
||||
- keystore.seed
|
||||
- bootstrap.password
|
||||
- xpack.notification.slack.account.monitoring.secure_url
|
||||
- xpack.notification.slack.account.otheraccount.secure_url
|
||||
- xpack.watcher.encryption_key
|
||||
|
|
@ -1,31 +0,0 @@
|
|||
---
|
||||
|
||||
clusterName: "config"
|
||||
replicas: 1
|
||||
|
||||
extraEnvs:
|
||||
- name: ELASTIC_PASSWORD
|
||||
valueFrom:
|
||||
secretKeyRef:
|
||||
name: elastic-credentials
|
||||
key: password
|
||||
- name: ELASTIC_USERNAME
|
||||
valueFrom:
|
||||
secretKeyRef:
|
||||
name: elastic-credentials
|
||||
key: username
|
||||
|
||||
# This is just a dummy file to make sure that
|
||||
# the keystore can be mounted at the same time
|
||||
# as a custom elasticsearch.yml
|
||||
esConfig:
|
||||
elasticsearch.yml: |
|
||||
path.data: /usr/share/elasticsearch/data
|
||||
|
||||
keystore:
|
||||
- secretName: elastic-config-secret
|
||||
- secretName: elastic-config-slack
|
||||
- secretName: elastic-config-custom-path
|
||||
items:
|
||||
- key: slack_url
|
||||
path: xpack.notification.slack.account.otheraccount.secure_url
|
||||
|
|
@ -1 +0,0 @@
|
|||
supersecret
|
||||
|
|
@ -1,16 +0,0 @@
|
|||
default: test
|
||||
|
||||
include ../../../helpers/examples.mk
|
||||
|
||||
RELEASE := helm-es-default
|
||||
|
||||
install:
|
||||
helm upgrade --wait --timeout=600 --install $(RELEASE) ../../
|
||||
|
||||
restart:
|
||||
helm upgrade --set terminationGracePeriod=121 --wait --timeout=600 --install $(RELEASE) ../../
|
||||
|
||||
test: install goss
|
||||
|
||||
purge:
|
||||
helm del --purge $(RELEASE)
|
||||
|
|
@ -1,25 +0,0 @@
|
|||
# Default
|
||||
|
||||
This example deploy a 3 nodes Elasticsearch 7.8.1 cluster using
|
||||
[default values][].
|
||||
|
||||
|
||||
## Usage
|
||||
|
||||
* Deploy Elasticsearch chart with the default values: `make install`
|
||||
|
||||
* You can now setup a port forward to query Elasticsearch API:
|
||||
|
||||
```
|
||||
kubectl port-forward svc/elasticsearch-master 9200
|
||||
curl localhost:9200/_cat/indices
|
||||
```
|
||||
|
||||
|
||||
## Testing
|
||||
|
||||
You can also run [goss integration tests][] using `make test`
|
||||
|
||||
|
||||
[goss integration tests]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/default/test/goss.yaml
|
||||
[default values]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/values.yaml
|
||||
|
|
@ -1,19 +0,0 @@
|
|||
#!/usr/bin/env bash -x
|
||||
|
||||
kubectl proxy || true &
|
||||
|
||||
make &
|
||||
PROC_ID=$!
|
||||
|
||||
while kill -0 "$PROC_ID" >/dev/null 2>&1; do
|
||||
echo "PROCESS IS RUNNING"
|
||||
if curl --fail 'http://localhost:8001/api/v1/proxy/namespaces/default/services/elasticsearch-master:9200/_search' ; then
|
||||
echo "cluster is healthy"
|
||||
else
|
||||
echo "cluster not healthy!"
|
||||
exit 1
|
||||
fi
|
||||
sleep 1
|
||||
done
|
||||
echo "PROCESS TERMINATED"
|
||||
exit 0
|
||||
|
|
@ -1,39 +0,0 @@
|
|||
kernel-param:
|
||||
vm.max_map_count:
|
||||
value: '262144'
|
||||
|
||||
http:
|
||||
http://elasticsearch-master:9200/_cluster/health:
|
||||
status: 200
|
||||
timeout: 2000
|
||||
body:
|
||||
- 'green'
|
||||
- '"number_of_nodes":3'
|
||||
- '"number_of_data_nodes":3'
|
||||
|
||||
http://localhost:9200:
|
||||
status: 200
|
||||
timeout: 2000
|
||||
body:
|
||||
- '"number" : "7.8.1"'
|
||||
- '"cluster_name" : "elasticsearch"'
|
||||
- '"name" : "elasticsearch-master-0"'
|
||||
- 'You Know, for Search'
|
||||
|
||||
file:
|
||||
/usr/share/elasticsearch/data:
|
||||
exists: true
|
||||
mode: "2775"
|
||||
owner: root
|
||||
group: elasticsearch
|
||||
filetype: directory
|
||||
|
||||
mount:
|
||||
/usr/share/elasticsearch/data:
|
||||
exists: true
|
||||
|
||||
user:
|
||||
elasticsearch:
|
||||
exists: true
|
||||
uid: 1000
|
||||
gid: 1000
|
||||
|
|
@ -1,12 +0,0 @@
|
|||
default: test
|
||||
|
||||
RELEASE := helm-es-docker-for-mac
|
||||
|
||||
install:
|
||||
helm upgrade --wait --timeout=900 --install --values values.yaml $(RELEASE) ../../
|
||||
|
||||
test: install
|
||||
helm test $(RELEASE)
|
||||
|
||||
purge:
|
||||
helm del --purge $(RELEASE)
|
||||
|
|
@ -1,23 +0,0 @@
|
|||
# Docker for Mac
|
||||
|
||||
This example deploy a 3 nodes Elasticsearch 7.8.1 cluster on [Docker for Mac][]
|
||||
using [custom values][].
|
||||
|
||||
Note that this configuration should be used for test only and isn't recommended
|
||||
for production.
|
||||
|
||||
|
||||
## Usage
|
||||
|
||||
* Deploy Elasticsearch chart with the default values: `make install`
|
||||
|
||||
* You can now setup a port forward to query Elasticsearch API:
|
||||
|
||||
```
|
||||
kubectl port-forward svc/elasticsearch-master 9200
|
||||
curl localhost:9200/_cat/indices
|
||||
```
|
||||
|
||||
|
||||
[custom values]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/docker-for-mac/values.yaml
|
||||
[docker for mac]: https://docs.docker.com/docker-for-mac/kubernetes/
|
||||
|
|
@ -1,23 +0,0 @@
|
|||
---
|
||||
# Permit co-located instances for solitary minikube virtual machines.
|
||||
antiAffinity: "soft"
|
||||
|
||||
# Shrink default JVM heap.
|
||||
esJavaOpts: "-Xmx128m -Xms128m"
|
||||
|
||||
# Allocate smaller chunks of memory per pod.
|
||||
resources:
|
||||
requests:
|
||||
cpu: "100m"
|
||||
memory: "512M"
|
||||
limits:
|
||||
cpu: "1000m"
|
||||
memory: "512M"
|
||||
|
||||
# Request smaller persistent volumes.
|
||||
volumeClaimTemplate:
|
||||
accessModes: [ "ReadWriteOnce" ]
|
||||
storageClassName: "hostpath"
|
||||
resources:
|
||||
requests:
|
||||
storage: 100M
|
||||
|
|
@ -1,16 +0,0 @@
|
|||
default: test
|
||||
|
||||
RELEASE := helm-es-kind
|
||||
|
||||
install:
|
||||
helm upgrade --wait --timeout=900 --install --values values.yaml $(RELEASE) ../../
|
||||
|
||||
install-local-path:
|
||||
kubectl apply -f https://raw.githubusercontent.com/rancher/local-path-provisioner/master/deploy/local-path-storage.yaml
|
||||
helm upgrade --wait --timeout=900 --install --values values-local-path.yaml $(RELEASE) ../../
|
||||
|
||||
test: install
|
||||
helm test $(RELEASE)
|
||||
|
||||
purge:
|
||||
helm del --purge $(RELEASE)
|
||||
|
|
@ -1,36 +0,0 @@
|
|||
# KIND
|
||||
|
||||
This example deploy a 3 nodes Elasticsearch 7.8.1 cluster on [Kind][]
|
||||
using [custom values][].
|
||||
|
||||
Note that this configuration should be used for test only and isn't recommended
|
||||
for production.
|
||||
|
||||
Note that Kind < 0.7.0 are affected by a [kind issue][] with mount points
|
||||
created from PVCs not writable by non-root users. [kubernetes-sigs/kind#1157][]
|
||||
fix it in Kind 0.7.0.
|
||||
|
||||
The workaround for Kind < 0.7.0 is to install manually
|
||||
[Rancher Local Path Provisioner][] and use `local-path` storage class for
|
||||
Elasticsearch volumes (see [Makefile][] instructions).
|
||||
|
||||
|
||||
## Usage
|
||||
|
||||
* For Kind >= 0.7.0: Deploy Elasticsearch chart with the default values: `make install`
|
||||
* For Kind < 0.7.0: Deploy Elasticsearch chart with `local-path` storage class: `make install-local-path`
|
||||
|
||||
* You can now setup a port forward to query Elasticsearch API:
|
||||
|
||||
```
|
||||
kubectl port-forward svc/elasticsearch-master 9200
|
||||
curl localhost:9200/_cat/indices
|
||||
```
|
||||
|
||||
|
||||
[custom values]: https://github.com/elastic/helm-charts/blob/7.8/elasticsearch/examples/kubernetes-kind/values.yaml
|
||||
[kind]: https://kind.sigs.k8s.io/
|
||||
[kind issue]: https://github.com/kubernetes-sigs/kind/issues/830
|
||||
[kubernetes-sigs/kind#1157]: https://github.com/kubernetes-sigs/kind/pull/1157
|
||||
[rancher local path provisioner]: https://github.com/rancher/local-path-provisioner
|
||||
[Makefile]: https://github.com/elastic/helm-charts/blob/7.8/elasticsearch/examples/kubernetes-kind/Makefile#L5
|
||||
|
|
@ -1,23 +0,0 @@
|
|||
---
|
||||
# Permit co-located instances for solitary minikube virtual machines.
|
||||
antiAffinity: "soft"
|
||||
|
||||
# Shrink default JVM heap.
|
||||
esJavaOpts: "-Xmx128m -Xms128m"
|
||||
|
||||
# Allocate smaller chunks of memory per pod.
|
||||
resources:
|
||||
requests:
|
||||
cpu: "100m"
|
||||
memory: "512M"
|
||||
limits:
|
||||
cpu: "1000m"
|
||||
memory: "512M"
|
||||
|
||||
# Request smaller persistent volumes.
|
||||
volumeClaimTemplate:
|
||||
accessModes: [ "ReadWriteOnce" ]
|
||||
storageClassName: "local-path"
|
||||
resources:
|
||||
requests:
|
||||
storage: 100M
|
||||
|
|
@ -1,23 +0,0 @@
|
|||
---
|
||||
# Permit co-located instances for solitary minikube virtual machines.
|
||||
antiAffinity: "soft"
|
||||
|
||||
# Shrink default JVM heap.
|
||||
esJavaOpts: "-Xmx128m -Xms128m"
|
||||
|
||||
# Allocate smaller chunks of memory per pod.
|
||||
resources:
|
||||
requests:
|
||||
cpu: "100m"
|
||||
memory: "512M"
|
||||
limits:
|
||||
cpu: "1000m"
|
||||
memory: "512M"
|
||||
|
||||
# Request smaller persistent volumes.
|
||||
volumeClaimTemplate:
|
||||
accessModes: [ "ReadWriteOnce" ]
|
||||
storageClassName: "local-path"
|
||||
resources:
|
||||
requests:
|
||||
storage: 100M
|
||||
|
|
@ -1,12 +0,0 @@
|
|||
default: test
|
||||
|
||||
RELEASE := helm-es-microk8s
|
||||
|
||||
install:
|
||||
helm upgrade --wait --timeout=900 --install --values values.yaml $(RELEASE) ../../
|
||||
|
||||
test: install
|
||||
helm test $(RELEASE)
|
||||
|
||||
purge:
|
||||
helm del --purge $(RELEASE)
|
||||
|
|
@ -1,32 +0,0 @@
|
|||
# MicroK8S
|
||||
|
||||
This example deploy a 3 nodes Elasticsearch 7.8.1 cluster on [MicroK8S][]
|
||||
using [custom values][].
|
||||
|
||||
Note that this configuration should be used for test only and isn't recommended
|
||||
for production.
|
||||
|
||||
|
||||
## Requirements
|
||||
|
||||
The following MicroK8S [addons][] need to be enabled:
|
||||
- `dns`
|
||||
- `helm`
|
||||
- `storage`
|
||||
|
||||
|
||||
## Usage
|
||||
|
||||
* Deploy Elasticsearch chart with the default values: `make install`
|
||||
|
||||
* You can now setup a port forward to query Elasticsearch API:
|
||||
|
||||
```
|
||||
kubectl port-forward svc/elasticsearch-master 9200
|
||||
curl localhost:9200/_cat/indices
|
||||
```
|
||||
|
||||
|
||||
[addons]: https://microk8s.io/docs/addons
|
||||
[custom values]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/microk8s/values.yaml
|
||||
[MicroK8S]: https://microk8s.io
|
||||
|
|
@ -1,32 +0,0 @@
|
|||
---
|
||||
# Disable privileged init Container creation.
|
||||
sysctlInitContainer:
|
||||
enabled: false
|
||||
|
||||
# Restrict the use of the memory-mapping when sysctlInitContainer is disabled.
|
||||
esConfig:
|
||||
elasticsearch.yml: |
|
||||
node.store.allow_mmap: false
|
||||
|
||||
# Permit co-located instances for solitary minikube virtual machines.
|
||||
antiAffinity: "soft"
|
||||
|
||||
# Shrink default JVM heap.
|
||||
esJavaOpts: "-Xmx128m -Xms128m"
|
||||
|
||||
# Allocate smaller chunks of memory per pod.
|
||||
resources:
|
||||
requests:
|
||||
cpu: "100m"
|
||||
memory: "512M"
|
||||
limits:
|
||||
cpu: "1000m"
|
||||
memory: "512M"
|
||||
|
||||
# Request smaller persistent volumes.
|
||||
volumeClaimTemplate:
|
||||
accessModes: [ "ReadWriteOnce" ]
|
||||
storageClassName: "microk8s-hostpath"
|
||||
resources:
|
||||
requests:
|
||||
storage: 100M
|
||||
|
|
@ -1,10 +0,0 @@
|
|||
PREFIX := helm-es-migration
|
||||
|
||||
data:
|
||||
helm upgrade --wait --timeout=600 --install --values ./data.yml $(PREFIX)-data ../../
|
||||
|
||||
master:
|
||||
helm upgrade --wait --timeout=600 --install --values ./master.yml $(PREFIX)-master ../../
|
||||
|
||||
client:
|
||||
helm upgrade --wait --timeout=600 --install --values ./client.yml $(PREFIX)-client ../../
|
||||
|
|
@ -1,167 +0,0 @@
|
|||
# Migration Guide from helm/charts
|
||||
|
||||
There are two viable options for migrating from the community Elasticsearch Helm
|
||||
chart from the [helm/charts][] repo.
|
||||
|
||||
1. Restoring from Snapshot to a fresh cluster
|
||||
2. Live migration by joining a new cluster to the existing cluster.
|
||||
|
||||
## Restoring from Snapshot
|
||||
|
||||
This is the recommended and preferred option. The downside is that it will
|
||||
involve a period of write downtime during the migration. If you have a way to
|
||||
temporarily stop writes to your cluster then this is the way to go. This is also
|
||||
a lot simpler as it just involves launching a fresh cluster and restoring a
|
||||
snapshot following the [restoring to a different cluster guide][].
|
||||
|
||||
## Live migration
|
||||
|
||||
If restoring from a snapshot is not possible due to the write downtime then a
|
||||
live migration is also possible. It is very important to first test this in a
|
||||
testing environment to make sure you are comfortable with the process and fully
|
||||
understand what is happening.
|
||||
|
||||
This process will involve joining a new set of master, data and client nodes to
|
||||
an existing cluster that has been deployed using the [helm/charts][] community
|
||||
chart. Nodes will then be replaced one by one in a controlled fashion to
|
||||
decommission the old cluster.
|
||||
|
||||
This example will be using the default values for the existing helm/charts
|
||||
release and for the Elastic helm-charts release. If you have changed any of the
|
||||
default values then you will need to first make sure that your values are
|
||||
configured in a compatible way before starting the migration.
|
||||
|
||||
The process will involve a re-sync and a rolling restart of all of your data
|
||||
nodes. Therefore it is important to disable shard allocation and perform a synced
|
||||
flush like you normally would during any other rolling upgrade. See the
|
||||
[rolling upgrades guide][] for more information.
|
||||
|
||||
* The default image for this chart is
|
||||
`docker.elastic.co/elasticsearch/elasticsearch` which contains the default
|
||||
distribution of Elasticsearch with a [basic license][]. Make sure to update the
|
||||
`image` and `imageTag` values to the correct Docker image and Elasticsearch
|
||||
version that you currently have deployed.
|
||||
|
||||
* Convert your current helm/charts configuration into something that is
|
||||
compatible with this chart.
|
||||
|
||||
* Take a fresh snapshot of your cluster. If something goes wrong you want to be
|
||||
able to restore your data no matter what.
|
||||
|
||||
* Check that your clusters health is green. If not abort and make sure your
|
||||
cluster is healthy before continuing:
|
||||
|
||||
```
|
||||
curl localhost:9200/_cluster/health
|
||||
```
|
||||
|
||||
* Deploy new data nodes which will join the existing cluster. Take a look at the
|
||||
configuration in [data.yml][]:
|
||||
|
||||
```
|
||||
make data
|
||||
```
|
||||
|
||||
* Check that the new nodes have joined the cluster (run this and any other curl
|
||||
commands from within one of your pods):
|
||||
|
||||
```
|
||||
curl localhost:9200/_cat/nodes
|
||||
```
|
||||
|
||||
* Check that your cluster is still green. If so we can now start to scale down
|
||||
the existing data nodes. Assuming you have the default amount of data nodes (2)
|
||||
we now want to scale it down to 1:
|
||||
|
||||
```
|
||||
kubectl scale statefulsets my-release-elasticsearch-data --replicas=1
|
||||
```
|
||||
|
||||
* Wait for your cluster to become green again:
|
||||
|
||||
```
|
||||
watch 'curl -s localhost:9200/_cluster/health'
|
||||
```
|
||||
|
||||
* Once the cluster is green we can scale down again:
|
||||
|
||||
```
|
||||
kubectl scale statefulsets my-release-elasticsearch-data --replicas=0
|
||||
```
|
||||
|
||||
* Wait for the cluster to be green again.
|
||||
* OK. We now have all data nodes running in the new cluster. Time to replace the
|
||||
masters by firstly scaling down the masters from 3 to 2. Between each step make
|
||||
sure to wait for the cluster to become green again, and check with
|
||||
`curl localhost:9200/_cat/nodes` that you see the correct amount of master
|
||||
nodes. During this process we will always make sure to keep at least 2 master
|
||||
nodes as to not lose quorum:
|
||||
|
||||
```
|
||||
kubectl scale statefulsets my-release-elasticsearch-master --replicas=2
|
||||
```
|
||||
|
||||
* Now deploy a single new master so that we have 3 masters again. See
|
||||
[master.yml][] for the configuration:
|
||||
|
||||
```
|
||||
make master
|
||||
```
|
||||
|
||||
* Scale down old masters to 1:
|
||||
|
||||
```
|
||||
kubectl scale statefulsets my-release-elasticsearch-master --replicas=1
|
||||
```
|
||||
|
||||
* Edit the masters in [masters.yml][] to 2 and redeploy:
|
||||
|
||||
```
|
||||
make master
|
||||
```
|
||||
|
||||
* Scale down the old masters to 0:
|
||||
|
||||
```
|
||||
kubectl scale statefulsets my-release-elasticsearch-master --replicas=0
|
||||
```
|
||||
|
||||
* Edit the [masters.yml][] to have 3 replicas and remove the
|
||||
`discovery.zen.ping.unicast.hosts` entry from `extraEnvs` then redeploy the
|
||||
masters. This will make sure all 3 masters are running in the new cluster and
|
||||
are pointing at each other for discovery:
|
||||
|
||||
```
|
||||
make master
|
||||
```
|
||||
|
||||
* Remove the `discovery.zen.ping.unicast.hosts` entry from `extraEnvs` then
|
||||
redeploy the data nodes to make sure they are pointing at the new masters:
|
||||
|
||||
```
|
||||
make data
|
||||
```
|
||||
|
||||
* Deploy the client nodes:
|
||||
|
||||
```
|
||||
make client
|
||||
```
|
||||
|
||||
* Update any processes that are talking to the existing client nodes and point
|
||||
them to the new client nodes. Once this is done you can scale down the old
|
||||
client nodes:
|
||||
|
||||
```
|
||||
kubectl scale deployment my-release-elasticsearch-client --replicas=0
|
||||
```
|
||||
|
||||
* The migration should now be complete. After verifying that everything is
|
||||
working correctly you can cleanup leftover resources from your old cluster.
|
||||
|
||||
[basic license]: https://www.elastic.co/subscriptions
|
||||
[data.yml]: https://github.com/elastic/helm-charts/blob/7.8/elasticsearch/examples/migration/data.yml
|
||||
[helm/charts]: https://github.com/helm/charts/tree/master/stable/elasticsearch
|
||||
[master.yml]: https://github.com/elastic/helm-charts/blob/7.8/elasticsearch/examples/migration/master.yml
|
||||
[restoring to a different cluster guide]: https://www.elastic.co/guide/en/elasticsearch/reference/6.6/modules-snapshots.html#_restoring_to_a_different_cluster
|
||||
[rolling upgrades guide]: https://www.elastic.co/guide/en/elasticsearch/reference/6.6/rolling-upgrades.html
|
||||
|
|
@ -1,23 +0,0 @@
|
|||
---
|
||||
|
||||
replicas: 2
|
||||
|
||||
clusterName: "elasticsearch"
|
||||
nodeGroup: "client"
|
||||
|
||||
esMajorVersion: 6
|
||||
|
||||
roles:
|
||||
master: "false"
|
||||
ingest: "false"
|
||||
data: "false"
|
||||
|
||||
volumeClaimTemplate:
|
||||
accessModes: [ "ReadWriteOnce" ]
|
||||
storageClassName: "standard"
|
||||
resources:
|
||||
requests:
|
||||
storage: 1Gi # Currently needed till pvcs are made optional
|
||||
|
||||
persistence:
|
||||
enabled: false
|
||||
|
|
@ -1,17 +0,0 @@
|
|||
---
|
||||
|
||||
replicas: 2
|
||||
|
||||
esMajorVersion: 6
|
||||
|
||||
extraEnvs:
|
||||
- name: discovery.zen.ping.unicast.hosts
|
||||
value: "my-release-elasticsearch-discovery"
|
||||
|
||||
clusterName: "elasticsearch"
|
||||
nodeGroup: "data"
|
||||
|
||||
roles:
|
||||
master: "false"
|
||||
ingest: "false"
|
||||
data: "true"
|
||||
|
|
@ -1,26 +0,0 @@
|
|||
---
|
||||
|
||||
# Temporarily set to 3 so we can scale up/down the old a new cluster
|
||||
# one at a time whilst always keeping 3 masters running
|
||||
replicas: 1
|
||||
|
||||
esMajorVersion: 6
|
||||
|
||||
extraEnvs:
|
||||
- name: discovery.zen.ping.unicast.hosts
|
||||
value: "my-release-elasticsearch-discovery"
|
||||
|
||||
clusterName: "elasticsearch"
|
||||
nodeGroup: "master"
|
||||
|
||||
roles:
|
||||
master: "true"
|
||||
ingest: "false"
|
||||
data: "false"
|
||||
|
||||
volumeClaimTemplate:
|
||||
accessModes: [ "ReadWriteOnce" ]
|
||||
storageClassName: "standard"
|
||||
resources:
|
||||
requests:
|
||||
storage: 4Gi
|
||||
|
|
@ -1,12 +0,0 @@
|
|||
default: test
|
||||
|
||||
RELEASE := helm-es-minikube
|
||||
|
||||
install:
|
||||
helm upgrade --wait --timeout=900 --install --values values.yaml $(RELEASE) ../../
|
||||
|
||||
test: install
|
||||
helm test $(RELEASE)
|
||||
|
||||
purge:
|
||||
helm del --purge $(RELEASE)
|
||||
|
|
@ -1,38 +0,0 @@
|
|||
# Minikube
|
||||
|
||||
This example deploy a 3 nodes Elasticsearch 7.8.1 cluster on [Minikube][]
|
||||
using [custom values][].
|
||||
|
||||
If helm or kubectl timeouts occur, you may consider creating a minikube VM with
|
||||
more CPU cores or memory allocated.
|
||||
|
||||
Note that this configuration should be used for test only and isn't recommended
|
||||
for production.
|
||||
|
||||
|
||||
## Requirements
|
||||
|
||||
In order to properly support the required persistent volume claims for the
|
||||
Elasticsearch StatefulSet, the `default-storageclass` and `storage-provisioner`
|
||||
minikube addons must be enabled.
|
||||
|
||||
```
|
||||
minikube addons enable default-storageclass
|
||||
minikube addons enable storage-provisioner
|
||||
```
|
||||
|
||||
|
||||
## Usage
|
||||
|
||||
* Deploy Elasticsearch chart with the default values: `make install`
|
||||
|
||||
* You can now setup a port forward to query Elasticsearch API:
|
||||
|
||||
```
|
||||
kubectl port-forward svc/elasticsearch-master 9200
|
||||
curl localhost:9200/_cat/indices
|
||||
```
|
||||
|
||||
|
||||
[custom values]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/minikube/values.yaml
|
||||
[minikube]: https://minikube.sigs.k8s.io/docs/
|
||||
|
|
@ -1,23 +0,0 @@
|
|||
---
|
||||
# Permit co-located instances for solitary minikube virtual machines.
|
||||
antiAffinity: "soft"
|
||||
|
||||
# Shrink default JVM heap.
|
||||
esJavaOpts: "-Xmx128m -Xms128m"
|
||||
|
||||
# Allocate smaller chunks of memory per pod.
|
||||
resources:
|
||||
requests:
|
||||
cpu: "100m"
|
||||
memory: "512M"
|
||||
limits:
|
||||
cpu: "1000m"
|
||||
memory: "512M"
|
||||
|
||||
# Request smaller persistent volumes.
|
||||
volumeClaimTemplate:
|
||||
accessModes: [ "ReadWriteOnce" ]
|
||||
storageClassName: "standard"
|
||||
resources:
|
||||
requests:
|
||||
storage: 100M
|
||||
|
|
@ -1,16 +0,0 @@
|
|||
default: test
|
||||
|
||||
include ../../../helpers/examples.mk
|
||||
|
||||
PREFIX := helm-es-multi
|
||||
RELEASE := helm-es-multi-master
|
||||
|
||||
install:
|
||||
helm upgrade --wait --timeout=600 --install --values ./master.yml $(PREFIX)-master ../../
|
||||
helm upgrade --wait --timeout=600 --install --values ./data.yml $(PREFIX)-data ../../
|
||||
|
||||
test: install goss
|
||||
|
||||
purge:
|
||||
helm del --purge $(PREFIX)-master
|
||||
helm del --purge $(PREFIX)-data
|
||||
|
|
@ -1,27 +0,0 @@
|
|||
# Multi
|
||||
|
||||
This example deploy an Elasticsearch 7.8.1 cluster composed of 2 different Helm
|
||||
releases:
|
||||
|
||||
- `helm-es-multi-master` for the 3 master nodes using [master values][]
|
||||
- `helm-es-multi-data` for the 3 data nodes using [data values][]
|
||||
|
||||
## Usage
|
||||
|
||||
* Deploy the 2 Elasticsearch releases: `make install`
|
||||
|
||||
* You can now setup a port forward to query Elasticsearch API:
|
||||
|
||||
```
|
||||
kubectl port-forward svc/multi-master 9200
|
||||
curl -u elastic:changeme http://localhost:9200/_cat/indices
|
||||
```
|
||||
|
||||
## Testing
|
||||
|
||||
You can also run [goss integration tests][] using `make test`
|
||||
|
||||
|
||||
[data values]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/multi/data.yml
|
||||
[goss integration tests]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/multi/test/goss.yaml
|
||||
[master values]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/multi/master.yml
|
||||
|
|
@ -1,9 +0,0 @@
|
|||
---
|
||||
|
||||
clusterName: "multi"
|
||||
nodeGroup: "data"
|
||||
|
||||
roles:
|
||||
master: "false"
|
||||
ingest: "true"
|
||||
data: "true"
|
||||
|
|
@ -1,9 +0,0 @@
|
|||
---
|
||||
|
||||
clusterName: "multi"
|
||||
nodeGroup: "master"
|
||||
|
||||
roles:
|
||||
master: "true"
|
||||
ingest: "false"
|
||||
data: "false"
|
||||
|
|
@ -1,9 +0,0 @@
|
|||
http:
|
||||
http://localhost:9200/_cluster/health:
|
||||
status: 200
|
||||
timeout: 2000
|
||||
body:
|
||||
- 'green'
|
||||
- '"cluster_name":"multi"'
|
||||
- '"number_of_nodes":6'
|
||||
- '"number_of_data_nodes":3'
|
||||
|
|
@ -1,15 +0,0 @@
|
|||
default: test
|
||||
include ../../../helpers/examples.mk
|
||||
|
||||
RELEASE := elasticsearch
|
||||
|
||||
template:
|
||||
helm template --values ./values.yaml ../../
|
||||
|
||||
install:
|
||||
helm upgrade --wait --timeout=600 --install $(RELEASE) --values ./values.yaml ../../
|
||||
|
||||
test: install goss
|
||||
|
||||
purge:
|
||||
helm del --purge $(RELEASE)
|
||||
|
|
@ -1,24 +0,0 @@
|
|||
# OpenShift
|
||||
|
||||
This example deploy a 3 nodes Elasticsearch 7.8.1 cluster on [OpenShift][]
|
||||
using [custom values][].
|
||||
|
||||
## Usage
|
||||
|
||||
* Deploy Elasticsearch chart with the default values: `make install`
|
||||
|
||||
* You can now setup a port forward to query Elasticsearch API:
|
||||
|
||||
```
|
||||
kubectl port-forward svc/elasticsearch-master 9200
|
||||
curl localhost:9200/_cat/indices
|
||||
```
|
||||
|
||||
## Testing
|
||||
|
||||
You can also run [goss integration tests][] using `make test`
|
||||
|
||||
|
||||
[custom values]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/openshift/values.yaml
|
||||
[goss integration tests]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/openshift/test/goss.yaml
|
||||
[openshift]: https://www.openshift.com/
|
||||
|
|
@ -1,17 +0,0 @@
|
|||
http:
|
||||
http://localhost:9200/_cluster/health:
|
||||
status: 200
|
||||
timeout: 2000
|
||||
body:
|
||||
- 'green'
|
||||
- '"number_of_nodes":3'
|
||||
- '"number_of_data_nodes":3'
|
||||
|
||||
http://localhost:9200:
|
||||
status: 200
|
||||
timeout: 2000
|
||||
body:
|
||||
- '"number" : "7.8.1"'
|
||||
- '"cluster_name" : "elasticsearch"'
|
||||
- '"name" : "elasticsearch-master-0"'
|
||||
- 'You Know, for Search'
|
||||
|
|
@ -1,11 +0,0 @@
|
|||
---
|
||||
|
||||
securityContext:
|
||||
runAsUser: null
|
||||
|
||||
podSecurityContext:
|
||||
fsGroup: null
|
||||
runAsUser: null
|
||||
|
||||
sysctlInitContainer:
|
||||
enabled: false
|
||||
|
|
@ -1,12 +0,0 @@
|
|||
default: test
|
||||
include ../../../helpers/examples.mk
|
||||
|
||||
RELEASE := helm-es-oss
|
||||
|
||||
install:
|
||||
helm upgrade --wait --timeout=600 --install $(RELEASE) --values ./values.yaml ../../
|
||||
|
||||
test: install goss
|
||||
|
||||
purge:
|
||||
helm del --purge $(RELEASE)
|
||||
|
|
@ -1,23 +0,0 @@
|
|||
# OSS
|
||||
|
||||
This example deploy a 3 nodes Elasticsearch 7.8.1 cluster using
|
||||
[Elasticsearch OSS][] version.
|
||||
|
||||
## Usage
|
||||
|
||||
* Deploy Elasticsearch chart with the default values: `make install`
|
||||
|
||||
* You can now setup a port forward to query Elasticsearch API:
|
||||
|
||||
```
|
||||
kubectl port-forward svc/oss-master 9200
|
||||
curl localhost:9200/_cat/indices
|
||||
```
|
||||
|
||||
## Testing
|
||||
|
||||
You can also run [goss integration tests][] using `make test`
|
||||
|
||||
|
||||
[elasticsearch oss]: https://www.elastic.co/downloads/elasticsearch-oss
|
||||
[goss integration tests]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/oss/test/goss.yaml
|
||||
|
|
@ -1,17 +0,0 @@
|
|||
http:
|
||||
http://localhost:9200/_cluster/health:
|
||||
status: 200
|
||||
timeout: 2000
|
||||
body:
|
||||
- 'green'
|
||||
- '"number_of_nodes":3'
|
||||
- '"number_of_data_nodes":3'
|
||||
|
||||
http://localhost:9200:
|
||||
status: 200
|
||||
timeout: 2000
|
||||
body:
|
||||
- '"number" : "7.8.1"'
|
||||
- '"cluster_name" : "oss"'
|
||||
- '"name" : "oss-master-0"'
|
||||
- 'You Know, for Search'
|
||||
|
|
@ -1,4 +0,0 @@
|
|||
---
|
||||
|
||||
clusterName: "oss"
|
||||
image: "docker.elastic.co/elasticsearch/elasticsearch-oss"
|
||||
|
|
@ -1,37 +0,0 @@
|
|||
default: test
|
||||
|
||||
include ../../../helpers/examples.mk
|
||||
|
||||
RELEASE := helm-es-security
|
||||
ELASTICSEARCH_IMAGE := docker.elastic.co/elasticsearch/elasticsearch:$(STACK_VERSION)
|
||||
|
||||
install:
|
||||
helm upgrade --wait --timeout=600 --install --values ./security.yml $(RELEASE) ../../
|
||||
|
||||
purge:
|
||||
kubectl delete secrets elastic-credentials elastic-certificates elastic-certificate-pem || true
|
||||
helm del --purge $(RELEASE)
|
||||
|
||||
test: secrets install goss
|
||||
|
||||
pull-elasticsearch-image:
|
||||
docker pull $(ELASTICSEARCH_IMAGE)
|
||||
|
||||
secrets:
|
||||
docker rm -f elastic-helm-charts-certs || true
|
||||
rm -f elastic-certificates.p12 elastic-certificate.pem elastic-certificate.crt elastic-stack-ca.p12 || true
|
||||
password=$$([ ! -z "$$ELASTIC_PASSWORD" ] && echo $$ELASTIC_PASSWORD || echo $$(docker run --rm busybox:1.31.1 /bin/sh -c "< /dev/urandom tr -cd '[:alnum:]' | head -c20")) && \
|
||||
docker run --name elastic-helm-charts-certs -i -w /app \
|
||||
$(ELASTICSEARCH_IMAGE) \
|
||||
/bin/sh -c " \
|
||||
elasticsearch-certutil ca --out /app/elastic-stack-ca.p12 --pass '' && \
|
||||
elasticsearch-certutil cert --name security-master --dns security-master --ca /app/elastic-stack-ca.p12 --pass '' --ca-pass '' --out /app/elastic-certificates.p12" && \
|
||||
docker cp elastic-helm-charts-certs:/app/elastic-certificates.p12 ./ && \
|
||||
docker rm -f elastic-helm-charts-certs && \
|
||||
openssl pkcs12 -nodes -passin pass:'' -in elastic-certificates.p12 -out elastic-certificate.pem && \
|
||||
openssl x509 -outform der -in elastic-certificate.pem -out elastic-certificate.crt && \
|
||||
kubectl create secret generic elastic-certificates --from-file=elastic-certificates.p12 && \
|
||||
kubectl create secret generic elastic-certificate-pem --from-file=elastic-certificate.pem && \
|
||||
kubectl create secret generic elastic-certificate-crt --from-file=elastic-certificate.crt && \
|
||||
kubectl create secret generic elastic-credentials --from-literal=password=$$password --from-literal=username=elastic && \
|
||||
rm -f elastic-certificates.p12 elastic-certificate.pem elastic-certificate.crt elastic-stack-ca.p12
|
||||
|
|
@ -1,29 +0,0 @@
|
|||
# Security
|
||||
|
||||
This example deploy a 3 nodes Elasticsearch 7.8.1 with authentication and
|
||||
autogenerated certificates for TLS (see [values][]).
|
||||
|
||||
Note that this configuration should be used for test only. For a production
|
||||
deployment you should generate SSL certificates following the [official docs][].
|
||||
|
||||
## Usage
|
||||
|
||||
* Create the required secrets: `make secrets`
|
||||
|
||||
* Deploy Elasticsearch chart with the default values: `make install`
|
||||
|
||||
* You can now setup a port forward to query Elasticsearch API:
|
||||
|
||||
```
|
||||
kubectl port-forward svc/security-master 9200
|
||||
curl -u elastic:changeme https://localhost:9200/_cat/indices
|
||||
```
|
||||
|
||||
## Testing
|
||||
|
||||
You can also run [goss integration tests][] using `make test`
|
||||
|
||||
|
||||
[goss integration tests]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/security/test/goss.yaml
|
||||
[official docs]: https://www.elastic.co/guide/en/elasticsearch/reference/7.8/configuring-tls.html#node-certificates
|
||||
[values]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/security/security.yaml
|
||||
|
|
@ -1,38 +0,0 @@
|
|||
---
|
||||
clusterName: "security"
|
||||
nodeGroup: "master"
|
||||
|
||||
roles:
|
||||
master: "true"
|
||||
ingest: "true"
|
||||
data: "true"
|
||||
|
||||
protocol: https
|
||||
|
||||
esConfig:
|
||||
elasticsearch.yml: |
|
||||
xpack.security.enabled: true
|
||||
xpack.security.transport.ssl.enabled: true
|
||||
xpack.security.transport.ssl.verification_mode: certificate
|
||||
xpack.security.transport.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
|
||||
xpack.security.transport.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
|
||||
xpack.security.http.ssl.enabled: true
|
||||
xpack.security.http.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
|
||||
xpack.security.http.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
|
||||
|
||||
extraEnvs:
|
||||
- name: ELASTIC_PASSWORD
|
||||
valueFrom:
|
||||
secretKeyRef:
|
||||
name: elastic-credentials
|
||||
key: password
|
||||
- name: ELASTIC_USERNAME
|
||||
valueFrom:
|
||||
secretKeyRef:
|
||||
name: elastic-credentials
|
||||
key: username
|
||||
|
||||
secretMounts:
|
||||
- name: elastic-certificates
|
||||
secretName: elastic-certificates
|
||||
path: /usr/share/elasticsearch/config/certs
|
||||
|
|
@ -1,45 +0,0 @@
|
|||
http:
|
||||
https://security-master:9200/_cluster/health:
|
||||
status: 200
|
||||
timeout: 2000
|
||||
allow-insecure: true
|
||||
username: '{{ .Env.ELASTIC_USERNAME }}'
|
||||
password: '{{ .Env.ELASTIC_PASSWORD }}'
|
||||
body:
|
||||
- 'green'
|
||||
- '"number_of_nodes":3'
|
||||
- '"number_of_data_nodes":3'
|
||||
|
||||
https://localhost:9200/:
|
||||
status: 200
|
||||
timeout: 2000
|
||||
allow-insecure: true
|
||||
username: '{{ .Env.ELASTIC_USERNAME }}'
|
||||
password: '{{ .Env.ELASTIC_PASSWORD }}'
|
||||
body:
|
||||
- '"cluster_name" : "security"'
|
||||
- '"name" : "security-master-0"'
|
||||
- 'You Know, for Search'
|
||||
|
||||
https://localhost:9200/_xpack/license:
|
||||
status: 200
|
||||
timeout: 2000
|
||||
allow-insecure: true
|
||||
username: '{{ .Env.ELASTIC_USERNAME }}'
|
||||
password: '{{ .Env.ELASTIC_PASSWORD }}'
|
||||
body:
|
||||
- 'active'
|
||||
- 'basic'
|
||||
|
||||
file:
|
||||
/usr/share/elasticsearch/config/elasticsearch.yml:
|
||||
exists: true
|
||||
contains:
|
||||
- 'xpack.security.enabled: true'
|
||||
- 'xpack.security.transport.ssl.enabled: true'
|
||||
- 'xpack.security.transport.ssl.verification_mode: certificate'
|
||||
- 'xpack.security.transport.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12'
|
||||
- 'xpack.security.transport.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12'
|
||||
- 'xpack.security.http.ssl.enabled: true'
|
||||
- 'xpack.security.http.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12'
|
||||
- 'xpack.security.http.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12'
|
||||
|
|
@ -1,16 +0,0 @@
|
|||
default: test
|
||||
|
||||
include ../../../helpers/examples.mk
|
||||
|
||||
RELEASE := helm-es-upgrade
|
||||
|
||||
install:
|
||||
./scripts/upgrade.sh --release $(RELEASE)
|
||||
|
||||
init:
|
||||
helm init --client-only
|
||||
|
||||
test: init install goss
|
||||
|
||||
purge:
|
||||
helm del --purge $(RELEASE)
|
||||
|
|
@ -1,27 +0,0 @@
|
|||
# Upgrade
|
||||
|
||||
This example will deploy a 3 node Elasticsearch cluster using an old chart version,
|
||||
then upgrade it to version 7.8.1.
|
||||
|
||||
The following upgrades are tested:
|
||||
- Upgrade from [7.0.0-alpha1][] version on K8S <1.16
|
||||
- Upgrade from [7.4.0][] version on K8S >=1.16 (Elasticsearch chart < 7.4.0 are
|
||||
not compatible with K8S >= 1.16)
|
||||
|
||||
|
||||
## Usage
|
||||
|
||||
Running `make install` command will do first install and 7.8.1 upgrade.
|
||||
|
||||
Note: [jq][] is a requirement for this make target.
|
||||
|
||||
|
||||
## Testing
|
||||
|
||||
You can also run [goss integration tests][] using `make test`.
|
||||
|
||||
|
||||
[7.0.0-alpha1]: https://github.com/elastic/helm-charts/releases/tag/7.0.0-alpha1
|
||||
[7.4.0]: https://github.com/elastic/helm-charts/releases/tag/7.4.0
|
||||
[goss integration tests]: https://github.com/elastic/helm-charts/tree/7.8/elasticsearch/examples/upgrade/test/goss.yaml
|
||||
[jq]: https://stedolan.github.io/jq/
|
||||
|
|
@ -1,76 +0,0 @@
|
|||
#!/usr/bin/env bash
|
||||
|
||||
set -euo pipefail
|
||||
|
||||
usage() {
|
||||
cat <<-EOF
|
||||
USAGE:
|
||||
$0 [--release <release-name>] [--from <elasticsearch-version>]
|
||||
$0 --help
|
||||
|
||||
OPTIONS:
|
||||
--release <release-name>
|
||||
Name of the Helm release to install
|
||||
--from <elasticsearch-version>
|
||||
Elasticsearch version to use for first install
|
||||
EOF
|
||||
exit 1
|
||||
}
|
||||
|
||||
RELEASE="helm-es-upgrade"
|
||||
FROM=""
|
||||
|
||||
while [[ $# -gt 0 ]]
|
||||
do
|
||||
key="$1"
|
||||
|
||||
case $key in
|
||||
--help)
|
||||
usage
|
||||
;;
|
||||
--release)
|
||||
RELEASE="$2"
|
||||
shift 2
|
||||
;;
|
||||
--from)
|
||||
FROM="$2"
|
||||
shift 2
|
||||
;;
|
||||
*)
|
||||
log "Unrecognized argument: '$key'"
|
||||
usage
|
||||
;;
|
||||
esac
|
||||
done
|
||||
|
||||
if ! command -v jq > /dev/null
|
||||
then
|
||||
echo 'jq is required to use this script'
|
||||
echo 'please check https://stedolan.github.io/jq/download/ to install it'
|
||||
exit 1
|
||||
fi
|
||||
|
||||
# Elasticsearch chart < 7.4.0 are not compatible with K8S >= 1.16)
|
||||
if [[ -z $FROM ]]
|
||||
then
|
||||
KUBE_MINOR_VERSION=$(kubectl version -o json | jq --raw-output --exit-status '.serverVersion.minor' | sed 's/[^0-9]*//g')
|
||||
|
||||
if [ "$KUBE_MINOR_VERSION" -lt 16 ]
|
||||
then
|
||||
FROM="7.0.0-alpha1"
|
||||
else
|
||||
FROM="7.4.0"
|
||||
fi
|
||||
fi
|
||||
|
||||
helm repo add elastic https://helm.elastic.co
|
||||
|
||||
# Initial install
|
||||
printf "Installing Elasticsearch chart %s\n" "$FROM"
|
||||
helm upgrade --wait --timeout=600 --install "$RELEASE" elastic/elasticsearch --version "$FROM" --set clusterName=upgrade
|
||||
kubectl rollout status sts/upgrade-master --timeout=600s
|
||||
|
||||
# Upgrade
|
||||
printf "Upgrading Elasticsearch chart\n"
|
||||
helm upgrade --wait --timeout=600 --set terminationGracePeriod=121 --install "$RELEASE" ../../ --set clusterName=upgrade
|
||||
kubectl rollout status sts/upgrade-master --timeout=600s
|
||||
|
|
@ -1,17 +0,0 @@
|
|||
http:
|
||||
http://localhost:9200/_cluster/health:
|
||||
status: 200
|
||||
timeout: 2000
|
||||
body:
|
||||
- 'green'
|
||||
- '"number_of_nodes":3'
|
||||
- '"number_of_data_nodes":3'
|
||||
|
||||
http://localhost:9200:
|
||||
status: 200
|
||||
timeout: 2000
|
||||
body:
|
||||
- '"number" : "7.8.1"'
|
||||
- '"cluster_name" : "upgrade"'
|
||||
- '"name" : "upgrade-master-0"'
|
||||
- 'You Know, for Search'
|
||||
|
|
@ -1,4 +0,0 @@
|
|||
1. Watch all cluster members come up.
|
||||
$ kubectl get pods --namespace={{ .Release.Namespace }} -l app={{ template "elasticsearch.uname" . }} -w
|
||||
2. Test cluster health using Helm test.
|
||||
$ helm test {{ .Release.Name }} --cleanup
|
||||
|
|
@ -1,87 +0,0 @@
|
|||
{{/* vim: set filetype=mustache: */}}
|
||||
{{/*
|
||||
Expand the name of the chart.
|
||||
*/}}
|
||||
{{- define "elasticsearch.name" -}}
|
||||
{{- default .Chart.Name .Values.nameOverride | trunc 63 | trimSuffix "-" -}}
|
||||
{{- end -}}
|
||||
|
||||
{{/*
|
||||
Create a default fully qualified app name.
|
||||
We truncate at 63 chars because some Kubernetes name fields are limited to this (by the DNS naming spec).
|
||||
*/}}
|
||||
{{- define "elasticsearch.fullname" -}}
|
||||
{{- $name := default .Chart.Name .Values.nameOverride -}}
|
||||
{{- printf "%s-%s" .Release.Name $name | trunc 63 | trimSuffix "-" -}}
|
||||
{{- end -}}
|
||||
|
||||
{{- define "elasticsearch.uname" -}}
|
||||
{{- if empty .Values.fullnameOverride -}}
|
||||
{{- if empty .Values.nameOverride -}}
|
||||
{{ .Values.clusterName }}-{{ .Values.nodeGroup }}
|
||||
{{- else -}}
|
||||
{{ .Values.nameOverride }}-{{ .Values.nodeGroup }}
|
||||
{{- end -}}
|
||||
{{- else -}}
|
||||
{{ .Values.fullnameOverride }}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
|
||||
{{- define "elasticsearch.masterService" -}}
|
||||
{{- if empty .Values.masterService -}}
|
||||
{{- if empty .Values.fullnameOverride -}}
|
||||
{{- if empty .Values.nameOverride -}}
|
||||
{{ .Values.clusterName }}-master
|
||||
{{- else -}}
|
||||
{{ .Values.nameOverride }}-master
|
||||
{{- end -}}
|
||||
{{- else -}}
|
||||
{{ .Values.fullnameOverride }}
|
||||
{{- end -}}
|
||||
{{- else -}}
|
||||
{{ .Values.masterService }}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
|
||||
{{- define "elasticsearch.endpoints" -}}
|
||||
{{- $replicas := int (toString (.Values.replicas)) }}
|
||||
{{- $uname := (include "elasticsearch.uname" .) }}
|
||||
{{- range $i, $e := untilStep 0 $replicas 1 -}}
|
||||
{{ $uname }}-{{ $i }},
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
|
||||
{{- define "elasticsearch.esMajorVersion" -}}
|
||||
{{- if .Values.esMajorVersion -}}
|
||||
{{ .Values.esMajorVersion }}
|
||||
{{- else -}}
|
||||
{{- $version := int (index (.Values.imageTag | splitList ".") 0) -}}
|
||||
{{- if and (contains "docker.elastic.co/elasticsearch/elasticsearch" .Values.image) (not (eq $version 0)) -}}
|
||||
{{ $version }}
|
||||
{{- else -}}
|
||||
7
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
|
||||
{{/*
|
||||
Return the appropriate apiVersion for statefulset.
|
||||
*/}}
|
||||
{{- define "elasticsearch.statefulset.apiVersion" -}}
|
||||
{{- if semverCompare "<1.9-0" .Capabilities.KubeVersion.GitVersion -}}
|
||||
{{- print "apps/v1beta2" -}}
|
||||
{{- else -}}
|
||||
{{- print "apps/v1" -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
|
||||
{{/*
|
||||
Return the appropriate apiVersion for ingress.
|
||||
*/}}
|
||||
{{- define "elasticsearch.ingress.apiVersion" -}}
|
||||
{{- if semverCompare "<1.14-0" .Capabilities.KubeVersion.GitVersion -}}
|
||||
{{- print "extensions/v1beta1" -}}
|
||||
{{- else -}}
|
||||
{{- print "networking.k8s.io/v1beta1" -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
|
|
@ -1,17 +0,0 @@
|
|||
{{- if .Values.esConfig }}
|
||||
apiVersion: v1
|
||||
kind: ConfigMap
|
||||
metadata:
|
||||
name: {{ template "elasticsearch.uname" . }}-config
|
||||
namespace: {{ .Release.Namespace }}
|
||||
labels:
|
||||
heritage: {{ .Release.Service | quote }}
|
||||
release: {{ .Release.Name | quote }}
|
||||
chart: "{{ .Chart.Name }}"
|
||||
app: "{{ template "elasticsearch.uname" . }}"
|
||||
data:
|
||||
{{- range $path, $config := .Values.esConfig }}
|
||||
{{ $path }}: |
|
||||
{{ $config | indent 4 -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
|
|
@ -1,39 +0,0 @@
|
|||
{{- if .Values.ingress.enabled -}}
|
||||
{{- $fullName := include "elasticsearch.uname" . -}}
|
||||
{{- $servicePort := .Values.httpPort -}}
|
||||
{{- $ingressPath := .Values.ingress.path -}}
|
||||
apiVersion: {{ template "elasticsearch.ingress.apiVersion" . }}
|
||||
kind: Ingress
|
||||
metadata:
|
||||
name: {{ $fullName }}
|
||||
namespace: {{ .Release.Namespace }}
|
||||
labels:
|
||||
app: {{ .Chart.Name }}
|
||||
release: {{ .Release.Name }}
|
||||
heritage: {{ .Release.Service }}
|
||||
{{- with .Values.ingress.annotations }}
|
||||
annotations:
|
||||
{{ toYaml . | indent 4 }}
|
||||
{{- end }}
|
||||
spec:
|
||||
{{- if .Values.ingress.tls }}
|
||||
tls:
|
||||
{{- range .Values.ingress.tls }}
|
||||
- hosts:
|
||||
{{- range .hosts }}
|
||||
- {{ . }}
|
||||
{{- end }}
|
||||
secretName: {{ .secretName }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
rules:
|
||||
{{- range .Values.ingress.hosts }}
|
||||
- host: {{ . }}
|
||||
http:
|
||||
paths:
|
||||
- path: {{ $ingressPath }}
|
||||
backend:
|
||||
serviceName: {{ $fullName }}
|
||||
servicePort: {{ $servicePort }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
|
|
@ -1,13 +0,0 @@
|
|||
---
|
||||
{{- if .Values.maxUnavailable }}
|
||||
apiVersion: policy/v1beta1
|
||||
kind: PodDisruptionBudget
|
||||
metadata:
|
||||
name: "{{ template "elasticsearch.uname" . }}-pdb"
|
||||
namespace: {{ .Release.Namespace }}
|
||||
spec:
|
||||
maxUnavailable: {{ .Values.maxUnavailable }}
|
||||
selector:
|
||||
matchLabels:
|
||||
app: "{{ template "elasticsearch.uname" . }}"
|
||||
{{- end }}
|
||||
|
|
@ -1,15 +0,0 @@
|
|||
{{- if .Values.podSecurityPolicy.create -}}
|
||||
{{- $fullName := include "elasticsearch.uname" . -}}
|
||||
apiVersion: policy/v1beta1
|
||||
kind: PodSecurityPolicy
|
||||
metadata:
|
||||
name: {{ default $fullName .Values.podSecurityPolicy.name | quote }}
|
||||
namespace: {{ .Release.Namespace }}
|
||||
labels:
|
||||
heritage: {{ .Release.Service | quote }}
|
||||
release: {{ .Release.Name | quote }}
|
||||
chart: "{{ .Chart.Name }}-{{ .Chart.Version }}"
|
||||
app: {{ $fullName | quote }}
|
||||
spec:
|
||||
{{ toYaml .Values.podSecurityPolicy.spec | indent 2 }}
|
||||
{{- end -}}
|
||||
|
|
@ -1,26 +0,0 @@
|
|||
{{- if .Values.rbac.create -}}
|
||||
{{- $fullName := include "elasticsearch.uname" . -}}
|
||||
apiVersion: rbac.authorization.k8s.io/v1
|
||||
kind: Role
|
||||
metadata:
|
||||
name: {{ $fullName | quote }}
|
||||
namespace: {{ .Release.Namespace }}
|
||||
labels:
|
||||
heritage: {{ .Release.Service | quote }}
|
||||
release: {{ .Release.Name | quote }}
|
||||
chart: "{{ .Chart.Name }}-{{ .Chart.Version }}"
|
||||
app: {{ $fullName | quote }}
|
||||
rules:
|
||||
- apiGroups:
|
||||
- extensions
|
||||
resources:
|
||||
- podsecuritypolicies
|
||||
resourceNames:
|
||||
{{- if eq .Values.podSecurityPolicy.name "" }}
|
||||
- {{ $fullName | quote }}
|
||||
{{- else }}
|
||||
- {{ .Values.podSecurityPolicy.name | quote }}
|
||||
{{- end }}
|
||||
verbs:
|
||||
- use
|
||||
{{- end -}}
|
||||
|
|
@ -1,25 +0,0 @@
|
|||
{{- if .Values.rbac.create -}}
|
||||
{{- $fullName := include "elasticsearch.uname" . -}}
|
||||
apiVersion: rbac.authorization.k8s.io/v1
|
||||
kind: RoleBinding
|
||||
metadata:
|
||||
name: {{ $fullName | quote }}
|
||||
namespace: {{ .Release.Namespace }}
|
||||
labels:
|
||||
heritage: {{ .Release.Service | quote }}
|
||||
release: {{ .Release.Name | quote }}
|
||||
chart: "{{ .Chart.Name }}-{{ .Chart.Version }}"
|
||||
app: {{ $fullName | quote }}
|
||||
subjects:
|
||||
- kind: ServiceAccount
|
||||
{{- if eq .Values.rbac.serviceAccountName "" }}
|
||||
name: {{ $fullName | quote }}
|
||||
{{- else }}
|
||||
name: {{ .Values.rbac.serviceAccountName | quote }}
|
||||
{{- end }}
|
||||
namespace: {{ .Release.Namespace }}
|
||||
roleRef:
|
||||
kind: Role
|
||||
name: {{ $fullName | quote }}
|
||||
apiGroup: rbac.authorization.k8s.io
|
||||
{{- end -}}
|
||||
|
|
@ -1,73 +0,0 @@
|
|||
---
|
||||
kind: Service
|
||||
apiVersion: v1
|
||||
metadata:
|
||||
{{- if eq .Values.nodeGroup "master" }}
|
||||
name: {{ template "elasticsearch.masterService" . }}
|
||||
{{- else }}
|
||||
name: {{ template "elasticsearch.uname" . }}
|
||||
{{- end }}
|
||||
namespace: {{ .Release.Namespace }}
|
||||
labels:
|
||||
heritage: {{ .Release.Service | quote }}
|
||||
release: {{ .Release.Name | quote }}
|
||||
chart: "{{ .Chart.Name }}"
|
||||
app: "{{ template "elasticsearch.uname" . }}"
|
||||
{{- if .Values.service.labels }}
|
||||
{{ toYaml .Values.service.labels | indent 4}}
|
||||
{{- end }}
|
||||
annotations:
|
||||
{{ toYaml .Values.service.annotations | indent 4 }}
|
||||
spec:
|
||||
type: {{ .Values.service.type }}
|
||||
selector:
|
||||
release: {{ .Release.Name | quote }}
|
||||
chart: "{{ .Chart.Name }}"
|
||||
app: "{{ template "elasticsearch.uname" . }}"
|
||||
ports:
|
||||
- name: {{ .Values.service.httpPortName | default "http" }}
|
||||
protocol: TCP
|
||||
port: {{ .Values.httpPort }}
|
||||
{{- if .Values.service.nodePort }}
|
||||
nodePort: {{ .Values.service.nodePort }}
|
||||
{{- end }}
|
||||
- name: {{ .Values.service.transportPortName | default "transport" }}
|
||||
protocol: TCP
|
||||
port: {{ .Values.transportPort }}
|
||||
{{- if .Values.service.loadBalancerIP }}
|
||||
loadBalancerIP: {{ .Values.service.loadBalancerIP }}
|
||||
{{- end }}
|
||||
{{- with .Values.service.loadBalancerSourceRanges }}
|
||||
loadBalancerSourceRanges:
|
||||
{{ toYaml . | indent 4 }}
|
||||
{{- end }}
|
||||
---
|
||||
kind: Service
|
||||
apiVersion: v1
|
||||
metadata:
|
||||
{{- if eq .Values.nodeGroup "master" }}
|
||||
name: {{ template "elasticsearch.masterService" . }}-headless
|
||||
{{- else }}
|
||||
name: {{ template "elasticsearch.uname" . }}-headless
|
||||
{{- end }}
|
||||
labels:
|
||||
heritage: {{ .Release.Service | quote }}
|
||||
release: {{ .Release.Name | quote }}
|
||||
chart: "{{ .Chart.Name }}"
|
||||
app: "{{ template "elasticsearch.uname" . }}"
|
||||
{{- if .Values.service.labelsHeadless }}
|
||||
{{ toYaml .Values.service.labelsHeadless | indent 4 }}
|
||||
{{- end }}
|
||||
annotations:
|
||||
service.alpha.kubernetes.io/tolerate-unready-endpoints: "true"
|
||||
spec:
|
||||
clusterIP: None # This is needed for statefulset hostnames like elasticsearch-0 to resolve
|
||||
# Create endpoints also if the related pod isn't ready
|
||||
publishNotReadyAddresses: true
|
||||
selector:
|
||||
app: "{{ template "elasticsearch.uname" . }}"
|
||||
ports:
|
||||
- name: {{ .Values.service.httpPortName | default "http" }}
|
||||
port: {{ .Values.httpPort }}
|
||||
- name: {{ .Values.service.transportPortName | default "transport" }}
|
||||
port: {{ .Values.transportPort }}
|
||||
|
|
@ -1,21 +0,0 @@
|
|||
{{- if .Values.rbac.create -}}
|
||||
{{- $fullName := include "elasticsearch.uname" . -}}
|
||||
apiVersion: v1
|
||||
kind: ServiceAccount
|
||||
metadata:
|
||||
{{- if eq .Values.rbac.serviceAccountName "" }}
|
||||
name: {{ $fullName | quote }}
|
||||
{{- else }}
|
||||
name: {{ .Values.rbac.serviceAccountName | quote }}
|
||||
{{- end }}
|
||||
namespace: {{ .Release.Namespace }}
|
||||
annotations:
|
||||
{{- with .Values.rbac.serviceAccountAnnotations }}
|
||||
{{- toYaml . | nindent 4 }}
|
||||
{{- end }}
|
||||
labels:
|
||||
heritage: {{ .Release.Service | quote }}
|
||||
release: {{ .Release.Name | quote }}
|
||||
chart: "{{ .Chart.Name }}-{{ .Chart.Version }}"
|
||||
app: {{ $fullName | quote }}
|
||||
{{- end -}}
|
||||
|
|
@ -1,430 +0,0 @@
|
|||
---
|
||||
apiVersion: {{ template "elasticsearch.statefulset.apiVersion" . }}
|
||||
kind: StatefulSet
|
||||
metadata:
|
||||
name: {{ template "elasticsearch.uname" . }}
|
||||
namespace: {{ .Release.Namespace }}
|
||||
labels:
|
||||
heritage: {{ .Release.Service | quote }}
|
||||
release: {{ .Release.Name | quote }}
|
||||
chart: "{{ .Chart.Name }}"
|
||||
app: "{{ template "elasticsearch.uname" . }}"
|
||||
{{- range $key, $value := .Values.labels }}
|
||||
{{ $key }}: {{ $value | quote }}
|
||||
{{- end }}
|
||||
annotations:
|
||||
esMajorVersion: "{{ include "elasticsearch.esMajorVersion" . }}"
|
||||
spec:
|
||||
serviceName: {{ template "elasticsearch.uname" . }}-headless
|
||||
selector:
|
||||
matchLabels:
|
||||
app: "{{ template "elasticsearch.uname" . }}"
|
||||
replicas: {{ .Values.replicas }}
|
||||
podManagementPolicy: {{ .Values.podManagementPolicy }}
|
||||
updateStrategy:
|
||||
type: {{ .Values.updateStrategy }}
|
||||
{{- if .Values.persistence.enabled }}
|
||||
volumeClaimTemplates:
|
||||
- metadata:
|
||||
name: {{ template "elasticsearch.uname" . }}
|
||||
{{- if .Values.persistence.labels.enabled }}
|
||||
labels:
|
||||
heritage: {{ .Release.Service | quote }}
|
||||
release: {{ .Release.Name | quote }}
|
||||
chart: "{{ .Chart.Name }}"
|
||||
app: "{{ template "elasticsearch.uname" . }}"
|
||||
{{- range $key, $value := .Values.labels }}
|
||||
{{ $key }}: {{ $value | quote }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
{{- with .Values.persistence.annotations }}
|
||||
annotations:
|
||||
{{ toYaml . | indent 8 }}
|
||||
{{- end }}
|
||||
spec:
|
||||
{{ toYaml .Values.volumeClaimTemplate | indent 6 }}
|
||||
{{- end }}
|
||||
template:
|
||||
metadata:
|
||||
name: "{{ template "elasticsearch.uname" . }}"
|
||||
labels:
|
||||
heritage: {{ .Release.Service | quote }}
|
||||
release: {{ .Release.Name | quote }}
|
||||
chart: "{{ .Chart.Name }}"
|
||||
app: "{{ template "elasticsearch.uname" . }}"
|
||||
{{- range $key, $value := .Values.labels }}
|
||||
{{ $key }}: {{ $value | quote }}
|
||||
{{- end }}
|
||||
annotations:
|
||||
{{- range $key, $value := .Values.podAnnotations }}
|
||||
{{ $key }}: {{ $value | quote }}
|
||||
{{- end }}
|
||||
{{/* This forces a restart if the configmap has changed */}}
|
||||
{{- if .Values.esConfig }}
|
||||
configchecksum: {{ include (print .Template.BasePath "/configmap.yaml") . | sha256sum | trunc 63 }}
|
||||
{{- end }}
|
||||
spec:
|
||||
{{- if .Values.schedulerName }}
|
||||
schedulerName: "{{ .Values.schedulerName }}"
|
||||
{{- end }}
|
||||
securityContext:
|
||||
{{ toYaml .Values.podSecurityContext | indent 8 }}
|
||||
{{- if .Values.fsGroup }}
|
||||
fsGroup: {{ .Values.fsGroup }} # Deprecated value, please use .Values.podSecurityContext.fsGroup
|
||||
{{- end }}
|
||||
{{- if .Values.rbac.create }}
|
||||
serviceAccountName: "{{ template "elasticsearch.uname" . }}"
|
||||
{{- else if not (eq .Values.rbac.serviceAccountName "") }}
|
||||
serviceAccountName: {{ .Values.rbac.serviceAccountName | quote }}
|
||||
{{- end }}
|
||||
{{- with .Values.tolerations }}
|
||||
tolerations:
|
||||
{{ toYaml . | indent 6 }}
|
||||
{{- end }}
|
||||
{{- with .Values.nodeSelector }}
|
||||
nodeSelector:
|
||||
{{ toYaml . | indent 8 }}
|
||||
{{- end }}
|
||||
{{- if or (eq .Values.antiAffinity "hard") (eq .Values.antiAffinity "soft") .Values.nodeAffinity }}
|
||||
{{- if .Values.priorityClassName }}
|
||||
priorityClassName: {{ .Values.priorityClassName }}
|
||||
{{- end }}
|
||||
affinity:
|
||||
{{- end }}
|
||||
{{- if eq .Values.antiAffinity "hard" }}
|
||||
podAntiAffinity:
|
||||
requiredDuringSchedulingIgnoredDuringExecution:
|
||||
- labelSelector:
|
||||
matchExpressions:
|
||||
- key: app
|
||||
operator: In
|
||||
values:
|
||||
- "{{ template "elasticsearch.uname" .}}"
|
||||
topologyKey: {{ .Values.antiAffinityTopologyKey }}
|
||||
{{- else if eq .Values.antiAffinity "soft" }}
|
||||
podAntiAffinity:
|
||||
preferredDuringSchedulingIgnoredDuringExecution:
|
||||
- weight: 1
|
||||
podAffinityTerm:
|
||||
topologyKey: {{ .Values.antiAffinityTopologyKey }}
|
||||
labelSelector:
|
||||
matchExpressions:
|
||||
- key: app
|
||||
operator: In
|
||||
values:
|
||||
- "{{ template "elasticsearch.uname" . }}"
|
||||
{{- end }}
|
||||
{{- with .Values.nodeAffinity }}
|
||||
nodeAffinity:
|
||||
{{ toYaml . | indent 10 }}
|
||||
{{- end }}
|
||||
terminationGracePeriodSeconds: {{ .Values.terminationGracePeriod }}
|
||||
volumes:
|
||||
{{- range .Values.secretMounts }}
|
||||
- name: {{ .name }}
|
||||
secret:
|
||||
secretName: {{ .secretName }}
|
||||
{{- if .defaultMode }}
|
||||
defaultMode: {{ .defaultMode }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
{{- if .Values.esConfig }}
|
||||
- name: esconfig
|
||||
configMap:
|
||||
name: {{ template "elasticsearch.uname" . }}-config
|
||||
{{- end }}
|
||||
{{- if .Values.keystore }}
|
||||
- name: keystore
|
||||
emptyDir: {}
|
||||
{{- range .Values.keystore }}
|
||||
- name: keystore-{{ .secretName }}
|
||||
secret: {{ toYaml . | nindent 12 }}
|
||||
{{- end }}
|
||||
{{ end }}
|
||||
{{- if .Values.extraVolumes }}
|
||||
# Currently some extra blocks accept strings
|
||||
# to continue with backwards compatibility this is being kept
|
||||
# whilst also allowing for yaml to be specified too.
|
||||
{{- if eq "string" (printf "%T" .Values.extraVolumes) }}
|
||||
{{ tpl .Values.extraVolumes . | indent 8 }}
|
||||
{{- else }}
|
||||
{{ toYaml .Values.extraVolumes | indent 8 }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
{{- if .Values.imagePullSecrets }}
|
||||
imagePullSecrets:
|
||||
{{ toYaml .Values.imagePullSecrets | indent 8 }}
|
||||
{{- end }}
|
||||
{{- if semverCompare ">1.13" .Capabilities.KubeVersion.GitVersion }}
|
||||
enableServiceLinks: {{ .Values.enableServiceLinks }}
|
||||
{{- end }}
|
||||
initContainers:
|
||||
{{- if .Values.sysctlInitContainer.enabled }}
|
||||
- name: configure-sysctl
|
||||
securityContext:
|
||||
runAsUser: 0
|
||||
privileged: true
|
||||
image: "{{ .Values.image }}:{{ .Values.imageTag }}"
|
||||
imagePullPolicy: "{{ .Values.imagePullPolicy }}"
|
||||
command: ["sysctl", "-w", "vm.max_map_count={{ .Values.sysctlVmMaxMapCount}}"]
|
||||
resources:
|
||||
{{ toYaml .Values.initResources | indent 10 }}
|
||||
{{- end }}
|
||||
{{ if .Values.keystore }}
|
||||
- name: keystore
|
||||
image: "{{ .Values.image }}:{{ .Values.imageTag }}"
|
||||
imagePullPolicy: "{{ .Values.imagePullPolicy }}"
|
||||
command:
|
||||
- sh
|
||||
- -c
|
||||
- |
|
||||
#!/usr/bin/env bash
|
||||
set -euo pipefail
|
||||
|
||||
elasticsearch-keystore create
|
||||
|
||||
for i in /tmp/keystoreSecrets/*/*; do
|
||||
key=$(basename $i)
|
||||
echo "Adding file $i to keystore key $key"
|
||||
elasticsearch-keystore add-file "$key" "$i"
|
||||
done
|
||||
|
||||
# Add the bootstrap password since otherwise the Elasticsearch entrypoint tries to do this on startup
|
||||
if [ ! -z ${ELASTIC_PASSWORD+x} ]; then
|
||||
echo 'Adding env $ELASTIC_PASSWORD to keystore as key bootstrap.password'
|
||||
echo "$ELASTIC_PASSWORD" | elasticsearch-keystore add -x bootstrap.password
|
||||
fi
|
||||
|
||||
cp -a /usr/share/elasticsearch/config/elasticsearch.keystore /tmp/keystore/
|
||||
env: {{ toYaml .Values.extraEnvs | nindent 10 }}
|
||||
envFrom: {{ toYaml .Values.envFrom | nindent 10 }}
|
||||
resources: {{ toYaml .Values.initResources | nindent 10 }}
|
||||
volumeMounts:
|
||||
- name: keystore
|
||||
mountPath: /tmp/keystore
|
||||
{{- range .Values.keystore }}
|
||||
- name: keystore-{{ .secretName }}
|
||||
mountPath: /tmp/keystoreSecrets/{{ .secretName }}
|
||||
{{- end }}
|
||||
{{ end }}
|
||||
{{- if .Values.extraInitContainers }}
|
||||
# Currently some extra blocks accept strings
|
||||
# to continue with backwards compatibility this is being kept
|
||||
# whilst also allowing for yaml to be specified too.
|
||||
{{- if eq "string" (printf "%T" .Values.extraInitContainers) }}
|
||||
{{ tpl .Values.extraInitContainers . | indent 6 }}
|
||||
{{- else }}
|
||||
{{ toYaml .Values.extraInitContainers | indent 6 }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
containers:
|
||||
- name: "{{ template "elasticsearch.name" . }}"
|
||||
securityContext:
|
||||
{{ toYaml .Values.securityContext | indent 10 }}
|
||||
image: "{{ .Values.image }}:{{ .Values.imageTag }}"
|
||||
imagePullPolicy: "{{ .Values.imagePullPolicy }}"
|
||||
readinessProbe:
|
||||
exec:
|
||||
command:
|
||||
- sh
|
||||
- -c
|
||||
- |
|
||||
#!/usr/bin/env bash -e
|
||||
# If the node is starting up wait for the cluster to be ready (request params: "{{ .Values.clusterHealthCheckParams }}" )
|
||||
# Once it has started only check that the node itself is responding
|
||||
START_FILE=/tmp/.es_start_file
|
||||
|
||||
http () {
|
||||
local path="${1}"
|
||||
local args="${2}"
|
||||
set -- -XGET -s
|
||||
|
||||
if [ "$args" != "" ]; then
|
||||
set -- "$@" $args
|
||||
fi
|
||||
|
||||
if [ -n "${ELASTIC_USERNAME}" ] && [ -n "${ELASTIC_PASSWORD}" ]; then
|
||||
set -- "$@" -u "${ELASTIC_USERNAME}:${ELASTIC_PASSWORD}"
|
||||
fi
|
||||
|
||||
curl --output /dev/null -k "$@" "{{ .Values.protocol }}://127.0.0.1:{{ .Values.httpPort }}${path}"
|
||||
}
|
||||
|
||||
if [ -f "${START_FILE}" ]; then
|
||||
echo 'Elasticsearch is already running, lets check the node is healthy'
|
||||
HTTP_CODE=$(http "/" "-w %{http_code}")
|
||||
RC=$?
|
||||
if [[ ${RC} -ne 0 ]]; then
|
||||
echo "curl --output /dev/null -k -XGET -s -w '%{http_code}' \${BASIC_AUTH} {{ .Values.protocol }}://127.0.0.1:{{ .Values.httpPort }}/ failed with RC ${RC}"
|
||||
exit ${RC}
|
||||
fi
|
||||
# ready if HTTP code 200, 503 is tolerable if ES version is 6.x
|
||||
if [[ ${HTTP_CODE} == "200" ]]; then
|
||||
exit 0
|
||||
elif [[ ${HTTP_CODE} == "503" && "{{ include "elasticsearch.esMajorVersion" . }}" == "6" ]]; then
|
||||
exit 0
|
||||
else
|
||||
echo "curl --output /dev/null -k -XGET -s -w '%{http_code}' \${BASIC_AUTH} {{ .Values.protocol }}://127.0.0.1:{{ .Values.httpPort }}/ failed with HTTP code ${HTTP_CODE}"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
else
|
||||
echo 'Waiting for elasticsearch cluster to become ready (request params: "{{ .Values.clusterHealthCheckParams }}" )'
|
||||
if http "/_cluster/health?{{ .Values.clusterHealthCheckParams }}" "--fail" ; then
|
||||
touch ${START_FILE}
|
||||
exit 0
|
||||
else
|
||||
echo 'Cluster is not yet ready (request params: "{{ .Values.clusterHealthCheckParams }}" )'
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
{{ toYaml .Values.readinessProbe | indent 10 }}
|
||||
ports:
|
||||
- name: http
|
||||
containerPort: {{ .Values.httpPort }}
|
||||
- name: transport
|
||||
containerPort: {{ .Values.transportPort }}
|
||||
resources:
|
||||
{{ toYaml .Values.resources | indent 10 }}
|
||||
env:
|
||||
- name: node.name
|
||||
valueFrom:
|
||||
fieldRef:
|
||||
fieldPath: metadata.name
|
||||
{{- if eq .Values.roles.master "true" }}
|
||||
{{- if ge (int (include "elasticsearch.esMajorVersion" .)) 7 }}
|
||||
- name: cluster.initial_master_nodes
|
||||
value: "{{ template "elasticsearch.endpoints" . }}"
|
||||
{{- else }}
|
||||
- name: discovery.zen.minimum_master_nodes
|
||||
value: "{{ .Values.minimumMasterNodes }}"
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
{{- if lt (int (include "elasticsearch.esMajorVersion" .)) 7 }}
|
||||
- name: discovery.zen.ping.unicast.hosts
|
||||
value: "{{ template "elasticsearch.masterService" . }}-headless"
|
||||
{{- else }}
|
||||
- name: discovery.seed_hosts
|
||||
value: "{{ template "elasticsearch.masterService" . }}-headless"
|
||||
{{- end }}
|
||||
- name: cluster.name
|
||||
value: "{{ .Values.clusterName }}"
|
||||
- name: network.host
|
||||
value: "{{ .Values.networkHost }}"
|
||||
- name: ES_JAVA_OPTS
|
||||
value: "{{ .Values.esJavaOpts }}"
|
||||
{{- range $role, $enabled := .Values.roles }}
|
||||
- name: node.{{ $role }}
|
||||
value: "{{ $enabled }}"
|
||||
{{- end }}
|
||||
{{- if .Values.extraEnvs }}
|
||||
{{ toYaml .Values.extraEnvs | indent 10 }}
|
||||
{{- end }}
|
||||
{{- if .Values.envFrom }}
|
||||
envFrom:
|
||||
{{ toYaml .Values.envFrom | indent 10 }}
|
||||
{{- end }}
|
||||
volumeMounts:
|
||||
{{- if .Values.persistence.enabled }}
|
||||
- name: "{{ template "elasticsearch.uname" . }}"
|
||||
mountPath: /usr/share/elasticsearch/data
|
||||
{{- end }}
|
||||
{{ if .Values.keystore }}
|
||||
- name: keystore
|
||||
mountPath: /usr/share/elasticsearch/config/elasticsearch.keystore
|
||||
subPath: elasticsearch.keystore
|
||||
{{ end }}
|
||||
{{- range .Values.secretMounts }}
|
||||
- name: {{ .name }}
|
||||
mountPath: {{ .path }}
|
||||
{{- if .subPath }}
|
||||
subPath: {{ .subPath }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
{{- range $path, $config := .Values.esConfig }}
|
||||
- name: esconfig
|
||||
mountPath: /usr/share/elasticsearch/config/{{ $path }}
|
||||
subPath: {{ $path }}
|
||||
{{- end -}}
|
||||
{{- if .Values.extraVolumeMounts }}
|
||||
# Currently some extra blocks accept strings
|
||||
# to continue with backwards compatibility this is being kept
|
||||
# whilst also allowing for yaml to be specified too.
|
||||
{{- if eq "string" (printf "%T" .Values.extraVolumeMounts) }}
|
||||
{{ tpl .Values.extraVolumeMounts . | indent 10 }}
|
||||
{{- else }}
|
||||
{{ toYaml .Values.extraVolumeMounts | indent 10 }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
{{- if .Values.masterTerminationFix }}
|
||||
{{- if eq .Values.roles.master "true" }}
|
||||
# This sidecar will prevent slow master re-election
|
||||
# https://github.com/elastic/helm-charts/issues/63
|
||||
- name: elasticsearch-master-graceful-termination-handler
|
||||
image: "{{ .Values.image }}:{{ .Values.imageTag }}"
|
||||
imagePullPolicy: "{{ .Values.imagePullPolicy }}"
|
||||
command:
|
||||
- "sh"
|
||||
- -c
|
||||
- |
|
||||
#!/usr/bin/env bash
|
||||
set -eo pipefail
|
||||
|
||||
http () {
|
||||
local path="${1}"
|
||||
if [ -n "${ELASTIC_USERNAME}" ] && [ -n "${ELASTIC_PASSWORD}" ]; then
|
||||
BASIC_AUTH="-u ${ELASTIC_USERNAME}:${ELASTIC_PASSWORD}"
|
||||
else
|
||||
BASIC_AUTH=''
|
||||
fi
|
||||
curl -XGET -s -k --fail ${BASIC_AUTH} {{ .Values.protocol }}://{{ template "elasticsearch.masterService" . }}:{{ .Values.httpPort }}${path}
|
||||
}
|
||||
|
||||
cleanup () {
|
||||
while true ; do
|
||||
local master="$(http "/_cat/master?h=node" || echo "")"
|
||||
if [[ $master == "{{ template "elasticsearch.masterService" . }}"* && $master != "${NODE_NAME}" ]]; then
|
||||
echo "This node is not master."
|
||||
break
|
||||
fi
|
||||
echo "This node is still master, waiting gracefully for it to step down"
|
||||
sleep 1
|
||||
done
|
||||
|
||||
exit 0
|
||||
}
|
||||
|
||||
trap cleanup SIGTERM
|
||||
|
||||
sleep infinity &
|
||||
wait $!
|
||||
resources:
|
||||
{{ toYaml .Values.sidecarResources | indent 10 }}
|
||||
env:
|
||||
- name: NODE_NAME
|
||||
valueFrom:
|
||||
fieldRef:
|
||||
fieldPath: metadata.name
|
||||
{{- if .Values.extraEnvs }}
|
||||
{{ toYaml .Values.extraEnvs | indent 10 }}
|
||||
{{- end }}
|
||||
{{- if .Values.envFrom }}
|
||||
envFrom:
|
||||
{{ toYaml .Values.envFrom | indent 10 }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
{{- if .Values.lifecycle }}
|
||||
lifecycle:
|
||||
{{ toYaml .Values.lifecycle | indent 10 }}
|
||||
{{- end }}
|
||||
{{- if .Values.extraContainers }}
|
||||
# Currently some extra blocks accept strings
|
||||
# to continue with backwards compatibility this is being kept
|
||||
# whilst also allowing for yaml to be specified too.
|
||||
{{- if eq "string" (printf "%T" .Values.extraContainers) }}
|
||||
{{ tpl .Values.extraContainers . | indent 6 }}
|
||||
{{- else }}
|
||||
{{ toYaml .Values.extraContainers | indent 6 }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
|
|
@ -1,25 +0,0 @@
|
|||
---
|
||||
apiVersion: v1
|
||||
kind: Pod
|
||||
metadata:
|
||||
name: "{{ .Release.Name }}-{{ randAlpha 5 | lower }}-test"
|
||||
annotations:
|
||||
"helm.sh/hook": test-success
|
||||
spec:
|
||||
securityContext:
|
||||
{{ toYaml .Values.podSecurityContext | indent 4 }}
|
||||
containers:
|
||||
- name: "{{ .Release.Name }}-{{ randAlpha 5 | lower }}-test"
|
||||
image: "{{ .Values.image }}:{{ .Values.imageTag }}"
|
||||
imagePullPolicy: "{{ .Values.imagePullPolicy }}"
|
||||
command:
|
||||
- "sh"
|
||||
- "-c"
|
||||
- |
|
||||
#!/usr/bin/env bash -e
|
||||
curl -XGET --fail '{{ template "elasticsearch.uname" . }}:{{ .Values.httpPort }}/_cluster/health?{{ .Values.clusterHealthCheckParams }}'
|
||||
{{- if .Values.imagePullSecrets }}
|
||||
imagePullSecrets:
|
||||
{{ toYaml .Values.imagePullSecrets | indent 4 }}
|
||||
{{- end }}
|
||||
restartPolicy: Never
|
||||
|
|
@ -1,277 +0,0 @@
|
|||
---
|
||||
clusterName: "elasticsearch"
|
||||
nodeGroup: "master"
|
||||
|
||||
# The service that non master groups will try to connect to when joining the cluster
|
||||
# This should be set to clusterName + "-" + nodeGroup for your master group
|
||||
masterService: ""
|
||||
|
||||
# Elasticsearch roles that will be applied to this nodeGroup
|
||||
# These will be set as environment variables. E.g. node.master=true
|
||||
roles:
|
||||
master: "true"
|
||||
ingest: "true"
|
||||
data: "true"
|
||||
|
||||
replicas: 3
|
||||
minimumMasterNodes: 2
|
||||
|
||||
esMajorVersion: ""
|
||||
|
||||
# Allows you to add any config files in /usr/share/elasticsearch/config/
|
||||
# such as elasticsearch.yml and log4j2.properties
|
||||
esConfig: {}
|
||||
# elasticsearch.yml: |
|
||||
# key:
|
||||
# nestedkey: value
|
||||
# log4j2.properties: |
|
||||
# key = value
|
||||
|
||||
# Extra environment variables to append to this nodeGroup
|
||||
# This will be appended to the current 'env:' key. You can use any of the kubernetes env
|
||||
# syntax here
|
||||
extraEnvs: []
|
||||
# - name: MY_ENVIRONMENT_VAR
|
||||
# value: the_value_goes_here
|
||||
|
||||
# Allows you to load environment variables from kubernetes secret or config map
|
||||
envFrom: []
|
||||
# - secretRef:
|
||||
# name: env-secret
|
||||
# - configMapRef:
|
||||
# name: config-map
|
||||
|
||||
# A list of secrets and their paths to mount inside the pod
|
||||
# This is useful for mounting certificates for security and for mounting
|
||||
# the X-Pack license
|
||||
secretMounts: []
|
||||
# - name: elastic-certificates
|
||||
# secretName: elastic-certificates
|
||||
# path: /usr/share/elasticsearch/config/certs
|
||||
# defaultMode: 0755
|
||||
|
||||
image: "docker.elastic.co/elasticsearch/elasticsearch"
|
||||
imageTag: "7.8.1"
|
||||
imagePullPolicy: "IfNotPresent"
|
||||
|
||||
podAnnotations: {}
|
||||
# iam.amazonaws.com/role: es-cluster
|
||||
|
||||
# additionals labels
|
||||
labels: {}
|
||||
|
||||
esJavaOpts: "-Xmx1g -Xms1g"
|
||||
|
||||
resources:
|
||||
requests:
|
||||
cpu: "1000m"
|
||||
memory: "2Gi"
|
||||
limits:
|
||||
cpu: "1000m"
|
||||
memory: "2Gi"
|
||||
|
||||
initResources: {}
|
||||
# limits:
|
||||
# cpu: "25m"
|
||||
# # memory: "128Mi"
|
||||
# requests:
|
||||
# cpu: "25m"
|
||||
# memory: "128Mi"
|
||||
|
||||
sidecarResources: {}
|
||||
# limits:
|
||||
# cpu: "25m"
|
||||
# # memory: "128Mi"
|
||||
# requests:
|
||||
# cpu: "25m"
|
||||
# memory: "128Mi"
|
||||
|
||||
networkHost: "0.0.0.0"
|
||||
|
||||
volumeClaimTemplate:
|
||||
accessModes: [ "ReadWriteOnce" ]
|
||||
resources:
|
||||
requests:
|
||||
storage: 30Gi
|
||||
|
||||
rbac:
|
||||
create: false
|
||||
serviceAccountAnnotations: {}
|
||||
serviceAccountName: ""
|
||||
|
||||
podSecurityPolicy:
|
||||
create: false
|
||||
name: ""
|
||||
spec:
|
||||
privileged: true
|
||||
fsGroup:
|
||||
rule: RunAsAny
|
||||
runAsUser:
|
||||
rule: RunAsAny
|
||||
seLinux:
|
||||
rule: RunAsAny
|
||||
supplementalGroups:
|
||||
rule: RunAsAny
|
||||
volumes:
|
||||
- secret
|
||||
- configMap
|
||||
- persistentVolumeClaim
|
||||
|
||||
persistence:
|
||||
enabled: true
|
||||
labels:
|
||||
# Add default labels for the volumeClaimTemplate fo the StatefulSet
|
||||
enabled: false
|
||||
annotations: {}
|
||||
|
||||
extraVolumes: []
|
||||
# - name: extras
|
||||
# emptyDir: {}
|
||||
|
||||
extraVolumeMounts: []
|
||||
# - name: extras
|
||||
# mountPath: /usr/share/extras
|
||||
# readOnly: true
|
||||
|
||||
extraContainers: []
|
||||
# - name: do-something
|
||||
# image: busybox
|
||||
# command: ['do', 'something']
|
||||
|
||||
extraInitContainers: []
|
||||
# - name: do-something
|
||||
# image: busybox
|
||||
# command: ['do', 'something']
|
||||
|
||||
# This is the PriorityClass settings as defined in
|
||||
# https://kubernetes.io/docs/concepts/configuration/pod-priority-preemption/#priorityclass
|
||||
priorityClassName: ""
|
||||
|
||||
# By default this will make sure two pods don't end up on the same node
|
||||
# Changing this to a region would allow you to spread pods across regions
|
||||
antiAffinityTopologyKey: "kubernetes.io/hostname"
|
||||
|
||||
# Hard means that by default pods will only be scheduled if there are enough nodes for them
|
||||
# and that they will never end up on the same node. Setting this to soft will do this "best effort"
|
||||
antiAffinity: "hard"
|
||||
|
||||
# This is the node affinity settings as defined in
|
||||
# https://kubernetes.io/docs/concepts/configuration/assign-pod-node/#node-affinity-beta-feature
|
||||
nodeAffinity: {}
|
||||
|
||||
# The default is to deploy all pods serially. By setting this to parallel all pods are started at
|
||||
# the same time when bootstrapping the cluster
|
||||
podManagementPolicy: "Parallel"
|
||||
|
||||
# The environment variables injected by service links are not used, but can lead to slow Elasticsearch boot times when
|
||||
# there are many services in the current namespace.
|
||||
# If you experience slow pod startups you probably want to set this to `false`.
|
||||
enableServiceLinks: true
|
||||
|
||||
protocol: http
|
||||
httpPort: 9200
|
||||
transportPort: 9300
|
||||
|
||||
service:
|
||||
labels: {}
|
||||
labelsHeadless: {}
|
||||
type: ClusterIP
|
||||
nodePort: ""
|
||||
annotations: {}
|
||||
httpPortName: http
|
||||
transportPortName: transport
|
||||
loadBalancerIP: ""
|
||||
loadBalancerSourceRanges: []
|
||||
|
||||
updateStrategy: RollingUpdate
|
||||
|
||||
# This is the max unavailable setting for the pod disruption budget
|
||||
# The default value of 1 will make sure that kubernetes won't allow more than 1
|
||||
# of your pods to be unavailable during maintenance
|
||||
maxUnavailable: 1
|
||||
|
||||
podSecurityContext:
|
||||
fsGroup: 1000
|
||||
runAsUser: 1000
|
||||
|
||||
securityContext:
|
||||
capabilities:
|
||||
drop:
|
||||
- ALL
|
||||
# readOnlyRootFilesystem: true
|
||||
runAsNonRoot: true
|
||||
runAsUser: 1000
|
||||
|
||||
# How long to wait for elasticsearch to stop gracefully
|
||||
terminationGracePeriod: 120
|
||||
|
||||
sysctlVmMaxMapCount: 262144
|
||||
|
||||
readinessProbe:
|
||||
failureThreshold: 3
|
||||
initialDelaySeconds: 10
|
||||
periodSeconds: 10
|
||||
successThreshold: 3
|
||||
timeoutSeconds: 5
|
||||
|
||||
# https://www.elastic.co/guide/en/elasticsearch/reference/7.8/cluster-health.html#request-params wait_for_status
|
||||
clusterHealthCheckParams: "wait_for_status=green&timeout=1s"
|
||||
|
||||
## Use an alternate scheduler.
|
||||
## ref: https://kubernetes.io/docs/tasks/administer-cluster/configure-multiple-schedulers/
|
||||
##
|
||||
schedulerName: ""
|
||||
|
||||
imagePullSecrets: []
|
||||
nodeSelector: {}
|
||||
tolerations: []
|
||||
|
||||
# Enabling this will publically expose your Elasticsearch instance.
|
||||
# Only enable this if you have security enabled on your cluster
|
||||
ingress:
|
||||
enabled: false
|
||||
annotations: {}
|
||||
# kubernetes.io/ingress.class: nginx
|
||||
# kubernetes.io/tls-acme: "true"
|
||||
path: /
|
||||
hosts:
|
||||
- chart-example.local
|
||||
tls: []
|
||||
# - secretName: chart-example-tls
|
||||
# hosts:
|
||||
# - chart-example.local
|
||||
|
||||
nameOverride: ""
|
||||
fullnameOverride: ""
|
||||
|
||||
# https://github.com/elastic/helm-charts/issues/63
|
||||
masterTerminationFix: false
|
||||
|
||||
lifecycle: {}
|
||||
# preStop:
|
||||
# exec:
|
||||
# command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
|
||||
# postStart:
|
||||
# exec:
|
||||
# command:
|
||||
# - bash
|
||||
# - -c
|
||||
# - |
|
||||
# #!/bin/bash
|
||||
# # Add a template to adjust number of shards/replicas
|
||||
# TEMPLATE_NAME=my_template
|
||||
# INDEX_PATTERN="logstash-*"
|
||||
# SHARD_COUNT=8
|
||||
# REPLICA_COUNT=1
|
||||
# ES_URL=http://localhost:9200
|
||||
# while [[ "$(curl -s -o /dev/null -w '%{http_code}\n' $ES_URL)" != "200" ]]; do sleep 1; done
|
||||
# curl -XPUT "$ES_URL/_template/$TEMPLATE_NAME" -H 'Content-Type: application/json' -d'{"index_patterns":['\""$INDEX_PATTERN"\"'],"settings":{"number_of_shards":'$SHARD_COUNT',"number_of_replicas":'$REPLICA_COUNT'}}'
|
||||
|
||||
sysctlInitContainer:
|
||||
enabled: true
|
||||
|
||||
keystore: []
|
||||
|
||||
# Deprecated
|
||||
# please use the above podSecurityContext.fsGroup instead
|
||||
fsGroup: ""
|
||||
Binary file not shown.
|
|
@ -1,21 +0,0 @@
|
|||
# Patterns to ignore when building packages.
|
||||
# This supports shell glob matching, relative path matching, and
|
||||
# negation (prefixed with !). Only one pattern per line.
|
||||
.DS_Store
|
||||
# Common VCS dirs
|
||||
.git/
|
||||
.gitignore
|
||||
.bzr/
|
||||
.bzrignore
|
||||
.hg/
|
||||
.hgignore
|
||||
.svn/
|
||||
# Common backup files
|
||||
*.swp
|
||||
*.bak
|
||||
*.tmp
|
||||
*~
|
||||
# Various IDEs
|
||||
.project
|
||||
.idea/
|
||||
*.tmproj
|
||||
|
|
@ -1,24 +0,0 @@
|
|||
apiVersion: v1
|
||||
appVersion: 5.0.1
|
||||
description: Apache Kafka is publish-subscribe messaging rethought as a distributed
|
||||
commit log.
|
||||
home: https://kafka.apache.org/
|
||||
icon: https://kafka.apache.org/images/logo.png
|
||||
keywords:
|
||||
- kafka
|
||||
- zookeeper
|
||||
- kafka statefulset
|
||||
maintainers:
|
||||
- email: faraaz@rationalizeit.us
|
||||
name: faraazkhan
|
||||
- email: marc.villacorta@gmail.com
|
||||
name: h0tbird
|
||||
- email: ben@spothero.com
|
||||
name: benjigoldberg
|
||||
name: kafka
|
||||
sources:
|
||||
- https://github.com/kubernetes/charts/tree/master/incubator/zookeeper
|
||||
- https://github.com/Yolean/kubernetes-kafka
|
||||
- https://github.com/confluentinc/cp-docker-images
|
||||
- https://github.com/apache/kafka
|
||||
version: 0.21.2
|
||||
|
|
@ -1,4 +0,0 @@
|
|||
approvers:
|
||||
- benjigoldberg
|
||||
reviewers:
|
||||
- benjigoldberg
|
||||
|
|
@ -1,434 +0,0 @@
|
|||
# Apache Kafka Helm Chart
|
||||
|
||||
This is an implementation of Kafka StatefulSet found here:
|
||||
|
||||
* https://github.com/Yolean/kubernetes-kafka
|
||||
|
||||
## Pre Requisites:
|
||||
|
||||
* Kubernetes 1.3 with alpha APIs enabled and support for storage classes
|
||||
|
||||
* PV support on underlying infrastructure
|
||||
|
||||
* Requires at least `v2.0.0-beta.1` version of helm to support
|
||||
dependency management with requirements.yaml
|
||||
|
||||
## StatefulSet Details
|
||||
|
||||
* https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/
|
||||
|
||||
## StatefulSet Caveats
|
||||
|
||||
* https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/#limitations
|
||||
|
||||
## Chart Details
|
||||
|
||||
This chart will do the following:
|
||||
|
||||
* Implement a dynamically scalable kafka cluster using Kubernetes StatefulSets
|
||||
|
||||
* Implement a dynamically scalable zookeeper cluster as another Kubernetes StatefulSet required for the Kafka cluster above
|
||||
|
||||
* Expose Kafka protocol endpoints via NodePort services (optional)
|
||||
|
||||
### Installing the Chart
|
||||
|
||||
To install the chart with the release name `my-kafka` in the default
|
||||
namespace:
|
||||
|
||||
```
|
||||
$ helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator
|
||||
$ helm install --name my-kafka incubator/kafka
|
||||
```
|
||||
|
||||
If using a dedicated namespace(recommended) then make sure the namespace
|
||||
exists with:
|
||||
|
||||
```
|
||||
$ helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator
|
||||
$ kubectl create ns kafka
|
||||
$ helm install --name my-kafka --namespace kafka incubator/kafka
|
||||
```
|
||||
|
||||
This chart includes a ZooKeeper chart as a dependency to the Kafka
|
||||
cluster in its `requirement.yaml` by default. The chart can be customized using the
|
||||
following configurable parameters:
|
||||
|
||||
| Parameter | Description | Default |
|
||||
|------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------|
|
||||
| `image` | Kafka Container image name | `confluentinc/cp-kafka` |
|
||||
| `imageTag` | Kafka Container image tag | `5.0.1` |
|
||||
| `imagePullPolicy` | Kafka Container pull policy | `IfNotPresent` |
|
||||
| `replicas` | Kafka Brokers | `3` |
|
||||
| `component` | Kafka k8s selector key | `kafka` |
|
||||
| `resources` | Kafka resource requests and limits | `{}` |
|
||||
| `securityContext` | Kafka containers security context | `{}` |
|
||||
| `kafkaHeapOptions` | Kafka broker JVM heap options | `-Xmx1G-Xms1G` |
|
||||
| `logSubPath` | Subpath under `persistence.mountPath` where kafka logs will be placed. | `logs` |
|
||||
| `schedulerName` | Name of Kubernetes scheduler (other than the default) | `nil` |
|
||||
| `serviceAccountName` | Name of Kubernetes serviceAccount. Useful when needing to pull images from custom repositories | `nil` |
|
||||
| `priorityClassName` | Name of Kubernetes Pod PriorityClass. https://kubernetes.io/docs/concepts/configuration/pod-priority-preemption/#priorityclass | `nil` |
|
||||
| `affinity` | Defines affinities and anti-affinities for pods as defined in: https://kubernetes.io/docs/concepts/configuration/assign-pod-node/#affinity-and-anti-affinity preferences | `{}` |
|
||||
| `tolerations` | List of node tolerations for the pods. https://kubernetes.io/docs/concepts/configuration/taint-and-toleration/ | `[]` |
|
||||
| `headless.annotations` | List of annotations for the headless service. https://kubernetes.io/docs/concepts/services-networking/service/#headless-services | `[]` |
|
||||
| `headless.targetPort` | Target port to be used for the headless service. This is not a required value. | `nil` |
|
||||
| `headless.port` | Port to be used for the headless service. https://kubernetes.io/docs/concepts/configuration/taint-and-toleration/ | `9092` |
|
||||
| `external.enabled` | If True, exposes Kafka brokers via NodePort (PLAINTEXT by default) | `false` |
|
||||
| `external.dns.useInternal` | If True, add Annotation for internal DNS service | `false` |
|
||||
| `external.dns.useExternal` | If True, add Annotation for external DNS service | `true` |
|
||||
| `external.servicePort` | TCP port configured at external services (one per pod) to relay from NodePort to the external listener port. | '19092' |
|
||||
| `external.firstListenerPort` | TCP port which is added pod index number to arrive at the port used for NodePort and external listener port. | '31090' |
|
||||
| `external.domain` | Domain in which to advertise Kafka external listeners. | `cluster.local` |
|
||||
| `external.type` | Service Type. | `NodePort` |
|
||||
| `external.distinct` | Distinct DNS entries for each created A record. | `false` |
|
||||
| `external.annotations` | Additional annotations for the external service. | `{}` |
|
||||
| `external.labels` | Additional labels for the external service. | `{}` |
|
||||
| `external.loadBalancerIP` | Add Static IP to the type Load Balancer. Depends on the provider if enabled | `[]`
|
||||
| `external.loadBalancerSourceRanges` | Add IP ranges that are allowed to access the Load Balancer. | `[]`
|
||||
| `podAnnotations` | Annotation to be added to Kafka pods | `{}` |
|
||||
| `podLabels` | Labels to be added to Kafka pods | `{}` |
|
||||
| `podDisruptionBudget` | Define a Disruption Budget for the Kafka Pods | `{}` |
|
||||
| `envOverrides` | Add additional Environment Variables in the dictionary format | `{ zookeeper.sasl.enabled: "False" }` |
|
||||
| `configurationOverrides` | `Kafka ` [configuration setting][brokerconfigs] overrides in the dictionary format | `{ "confluent.support.metrics.enable": false }` |
|
||||
| `secrets` | Pass any secrets to the kafka pods. Each secret will be passed as an environment variable by default. The secret can also be mounted to a specific path if required. Environment variable names are generated as: `<secretName>_<secretKey>` (All upper case) | `{}` |
|
||||
| `additionalPorts` | Additional ports to expose on brokers. Useful when the image exposes metrics (like prometheus, etc.) through a javaagent instead of a sidecar | `{}` |
|
||||
| `readinessProbe.initialDelaySeconds` | Number of seconds before probe is initiated. | `30` |
|
||||
| `readinessProbe.periodSeconds` | How often (in seconds) to perform the probe. | `10` |
|
||||
| `readinessProbe.timeoutSeconds` | Number of seconds after which the probe times out. | `5` |
|
||||
| `readinessProbe.successThreshold` | Minimum consecutive successes for the probe to be considered successful after having failed. | `1` |
|
||||
| `readinessProbe.failureThreshold` | After the probe fails this many times, pod will be marked Unready. | `3` |
|
||||
| `terminationGracePeriodSeconds` | Wait up to this many seconds for a broker to shut down gracefully, after which it is killed | `60` |
|
||||
| `updateStrategy` | StatefulSet update strategy to use. | `{ type: "OnDelete" }` |
|
||||
| `podManagementPolicy` | Start and stop pods in Parallel or OrderedReady (one-by-one.) Can not change after first release. | `OrderedReady` |
|
||||
| `persistence.enabled` | Use a PVC to persist data | `true` |
|
||||
| `persistence.size` | Size of data volume | `1Gi` |
|
||||
| `persistence.mountPath` | Mount path of data volume | `/opt/kafka/data` |
|
||||
| `persistence.storageClass` | Storage class of backing PVC | `nil` |
|
||||
| `jmx.configMap.enabled` | Enable the default ConfigMap for JMX | `true` |
|
||||
| `jmx.configMap.overrideConfig` | Allows config file to be generated by passing values to ConfigMap | `{}` |
|
||||
| `jmx.configMap.overrideName` | Allows setting the name of the ConfigMap to be used | `""` |
|
||||
| `jmx.port` | The jmx port which JMX style metrics are exposed (note: these are not scrapeable by Prometheus) | `5555` |
|
||||
| `jmx.whitelistObjectNames` | Allows setting which JMX objects you want to expose to via JMX stats to JMX Exporter | (see `values.yaml`) |
|
||||
| `nodeSelector` | Node labels for pod assignment | `{}` |
|
||||
| `prometheus.jmx.resources` | Allows setting resource limits for jmx sidecar container | `{}` |
|
||||
| `prometheus.jmx.enabled` | Whether or not to expose JMX metrics to Prometheus | `false` |
|
||||
| `prometheus.jmx.image` | JMX Exporter container image | `solsson/kafka-prometheus-jmx-exporter@sha256` |
|
||||
| `prometheus.jmx.imageTag` | JMX Exporter container image tag | `a23062396cd5af1acdf76512632c20ea6be76885dfc20cd9ff40fb23846557e8` |
|
||||
| `prometheus.jmx.interval` | Interval that Prometheus scrapes JMX metrics when using Prometheus Operator | `10s` |
|
||||
| `prometheus.jmx.scrapeTimeout` | Timeout that Prometheus scrapes JMX metrics when using Prometheus Operator | `10s` |
|
||||
| `prometheus.jmx.port` | JMX Exporter Port which exposes metrics in Prometheus format for scraping | `5556` |
|
||||
| `prometheus.kafka.enabled` | Whether or not to create a separate Kafka exporter | `false` |
|
||||
| `prometheus.kafka.image` | Kafka Exporter container image | `danielqsj/kafka-exporter` |
|
||||
| `prometheus.kafka.imageTag` | Kafka Exporter container image tag | `v1.2.0` |
|
||||
| `prometheus.kafka.interval` | Interval that Prometheus scrapes Kafka metrics when using Prometheus Operator | `10s` |
|
||||
| `prometheus.kafka.scrapeTimeout` | Timeout that Prometheus scrapes Kafka metrics when using Prometheus Operator | `10s` |
|
||||
| `prometheus.kafka.port` | Kafka Exporter Port which exposes metrics in Prometheus format for scraping | `9308` |
|
||||
| `prometheus.kafka.resources` | Allows setting resource limits for kafka-exporter pod | `{}` |
|
||||
| `prometheus.kafka.affinity` | Defines affinities and anti-affinities for pods as defined in: https://kubernetes.io/docs/concepts/configuration/assign-pod-node/#affinity-and-anti-affinity preferences | `{}` |
|
||||
| `prometheus.kafka.tolerations` | List of node tolerations for the pods. https://kubernetes.io/docs/concepts/configuration/taint-and-toleration/ | `[]` |
|
||||
| `prometheus.operator.enabled` | True if using the Prometheus Operator, False if not | `false` |
|
||||
| `prometheus.operator.serviceMonitor.namespace` | Namespace in which to install the ServiceMonitor resource. Default to kube-prometheus install. | `monitoring` |
|
||||
| `prometheus.operator.serviceMonitor.releaseNamespace` | Set namespace to release namespace. Default false | `false` |
|
||||
| `prometheus.operator.serviceMonitor.selector` | Default to kube-prometheus install (CoreOS recommended), but should be set according to Prometheus install | `{ prometheus: kube-prometheus }` |
|
||||
| `prometheus.operator.prometheusRule.enabled` | True to create a PrometheusRule resource for Prometheus Operator, False if not | `false` |
|
||||
| `prometheus.operator.prometheusRule.namespace` | Namespace in which to install the PrometheusRule resource. Default to kube-prometheus install. | `monitoring` |
|
||||
| `prometheus.operator.prometheusRule.releaseNamespace` | Set namespace to release namespace. Default false | `false` |
|
||||
| `prometheus.operator.prometheusRule.selector` | Default to kube-prometheus install (CoreOS recommended), but should be set according to Prometheus install | `{ prometheus: kube-prometheus }` |
|
||||
| `prometheus.operator.prometheusRule.rules` | Define the prometheus rules. See values file for examples | `{}` |
|
||||
| `configJob.backoffLimit` | Number of retries before considering kafka-config job as failed | `6` |
|
||||
| `topics` | List of topics to create & configure. Can specify name, partitions, replicationFactor, reassignPartitions, config. See values.yaml | `[]` (Empty list) |
|
||||
| `testsEnabled` | Enable/disable the chart's tests | `true` |
|
||||
| `zookeeper.enabled` | If True, installs Zookeeper Chart | `true` |
|
||||
| `zookeeper.resources` | Zookeeper resource requests and limits | `{}` |
|
||||
| `zookeeper.env` | Environmental variables provided to Zookeeper Zookeeper | `{ZK_HEAP_SIZE: "1G"}` |
|
||||
| `zookeeper.storage` | Zookeeper Persistent volume size | `2Gi` |
|
||||
| `zookeeper.image.PullPolicy` | Zookeeper Container pull policy | `IfNotPresent` |
|
||||
| `zookeeper.url` | URL of Zookeeper Cluster (unneeded if installing Zookeeper Chart) | `""` |
|
||||
| `zookeeper.port` | Port of Zookeeper Cluster | `2181` |
|
||||
| `zookeeper.affinity` | Defines affinities and anti-affinities for pods as defined in: https://kubernetes.io/docs/concepts/configuration/assign-pod-node/#affinity-and-anti-affinity preferences | `{}` |
|
||||
| `zookeeper.nodeSelector` | Node labels for pod assignment | `{}` |
|
||||
|
||||
Specify parameters using `--set key=value[,key=value]` argument to `helm install`
|
||||
|
||||
Alternatively a YAML file that specifies the values for the parameters can be provided like this:
|
||||
|
||||
```bash
|
||||
$ helm install --name my-kafka -f values.yaml incubator/kafka
|
||||
```
|
||||
|
||||
### Connecting to Kafka from inside Kubernetes
|
||||
|
||||
You can connect to Kafka by running a simple pod in the K8s cluster like this with a configuration like this:
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
kind: Pod
|
||||
metadata:
|
||||
name: testclient
|
||||
namespace: kafka
|
||||
spec:
|
||||
containers:
|
||||
- name: kafka
|
||||
image: solsson/kafka:0.11.0.0
|
||||
command:
|
||||
- sh
|
||||
- -c
|
||||
- "exec tail -f /dev/null"
|
||||
```
|
||||
|
||||
Once you have the testclient pod above running, you can list all kafka
|
||||
topics with:
|
||||
|
||||
` kubectl -n kafka exec -ti testclient -- ./bin/kafka-topics.sh --zookeeper
|
||||
my-release-zookeeper:2181 --list`
|
||||
|
||||
Where `my-release` is the name of your helm release.
|
||||
|
||||
## Extensions
|
||||
|
||||
Kafka has a rich ecosystem, with lots of tools. This sections is intended to compile all of those tools for which a corresponding Helm chart has already been created.
|
||||
|
||||
- [Schema-registry](https://github.com/kubernetes/charts/tree/master/incubator/schema-registry) - A confluent project that provides a serving layer for your metadata. It provides a RESTful interface for storing and retrieving Avro schemas.
|
||||
|
||||
## Connecting to Kafka from outside Kubernetes
|
||||
|
||||
### NodePort External Service Type
|
||||
|
||||
Review and optionally override to enable the example text concerned with external access in `values.yaml`.
|
||||
|
||||
Once configured, you should be able to reach Kafka via NodePorts, one per replica. In kops where private,
|
||||
topology is enabled, this feature publishes an internal round-robin DNS record using the following naming
|
||||
scheme. The external access feature of this chart was tested with kops on AWS using flannel networking.
|
||||
If you wish to enable external access to Kafka running in kops, your security groups will likely need to
|
||||
be adjusted to allow non-Kubernetes nodes (e.g. bastion) to access the Kafka external listener port range.
|
||||
|
||||
```
|
||||
{{ .Release.Name }}.{{ .Values.external.domain }}
|
||||
```
|
||||
|
||||
If `external.distinct` is set theses entries will be prefixed with the replica number or broker id.
|
||||
|
||||
```
|
||||
{{ .Release.Name }}-<BROKER_ID>.{{ .Values.external.domain }}
|
||||
```
|
||||
|
||||
Port numbers for external access used at container and NodePort are unique to each container in the StatefulSet.
|
||||
Using the default `external.firstListenerPort` number with a `replicas` value of `3`, the following
|
||||
container and NodePorts will be opened for external access: `31090`, `31091`, `31092`. All of these ports should
|
||||
be reachable from any host to NodePorts are exposed because Kubernetes routes each NodePort from entry node
|
||||
to pod/container listening on the same port (e.g. `31091`).
|
||||
|
||||
The `external.servicePort` at each external access service (one such service per pod) is a relay toward
|
||||
the a `containerPort` with a number matching its respective `NodePort`. The range of NodePorts is set, but
|
||||
should not actually listen, on all Kafka pods in the StatefulSet. As any given pod will listen only one
|
||||
such port at a time, setting the range at every Kafka pod is a reasonably safe configuration.
|
||||
|
||||
#### Example values.yml for external service type NodePort
|
||||
The + lines are with the updated values.
|
||||
```
|
||||
external:
|
||||
- enabled: false
|
||||
+ enabled: true
|
||||
# type can be either NodePort or LoadBalancer
|
||||
type: NodePort
|
||||
# annotations:
|
||||
@@ -170,14 +170,14 @@ configurationOverrides:
|
||||
##
|
||||
## Setting "advertised.listeners" here appends to "PLAINTEXT://${POD_IP}:9092,", ensure you update the domain
|
||||
## If external service type is Nodeport:
|
||||
- # "advertised.listeners": |-
|
||||
- # EXTERNAL://kafka.cluster.local:$((31090 + ${KAFKA_BROKER_ID}))
|
||||
+ "advertised.listeners": |-
|
||||
+ EXTERNAL://kafka.cluster.local:$((31090 + ${KAFKA_BROKER_ID}))
|
||||
## If external service type is LoadBalancer and distinct is true:
|
||||
# "advertised.listeners": |-
|
||||
# EXTERNAL://kafka-$((${KAFKA_BROKER_ID})).cluster.local:19092
|
||||
## If external service type is LoadBalancer and distinct is false:
|
||||
# "advertised.listeners": |-
|
||||
# EXTERNAL://EXTERNAL://${LOAD_BALANCER_IP}:31090
|
||||
## Uncomment to define the EXTERNAL Listener protocol
|
||||
- # "listener.security.protocol.map": |-
|
||||
- # PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
|
||||
+ "listener.security.protocol.map": |-
|
||||
+ PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
|
||||
|
||||
|
||||
$ kafkacat -b kafka.cluster.local:31090 -L
|
||||
Metadata for all topics (from broker 0: kafka.cluster.local:31090/0):
|
||||
3 brokers:
|
||||
broker 2 at kafka.cluster.local:31092
|
||||
broker 1 at kafka.cluster.local:31091
|
||||
broker 0 at kafka.cluster.local:31090
|
||||
0 topics:
|
||||
|
||||
$ kafkacat -b kafka.cluster.local:31090 -P -t test1 -p 0
|
||||
msg01 from external producer to topic test1
|
||||
|
||||
$ kafkacat -b kafka.cluster.local:31090 -C -t test1 -p 0
|
||||
msg01 from external producer to topic test1
|
||||
```
|
||||
### LoadBalancer External Service Type
|
||||
|
||||
The load balancer external service type differs from the node port type by routing to the `external.servicePort` specified in the service for each statefulset container (if `external.distinct` is set). If `external.distinct` is false, `external.servicePort` is unused and will be set to the sum of `external.firstListenerPort` and the replica number. It is important to note that `external.firstListenerPort` does not have to be within the configured node port range for the cluster, however a node port will be allocated.
|
||||
|
||||
#### Example values.yml and DNS setup for external service type LoadBalancer with external.distinct: true
|
||||
The + lines are with the updated values.
|
||||
```
|
||||
external:
|
||||
- enabled: false
|
||||
+ enabled: true
|
||||
# type can be either NodePort or LoadBalancer
|
||||
- type: NodePort
|
||||
+ type: LoadBalancer
|
||||
# annotations:
|
||||
# service.beta.kubernetes.io/openstack-internal-load-balancer: "true"
|
||||
dns:
|
||||
@@ -138,10 +138,10 @@ external:
|
||||
# If using external service type LoadBalancer and external dns, set distinct to true below.
|
||||
# This creates an A record for each statefulset pod/broker. You should then map the
|
||||
# A record of the broker to the EXTERNAL IP given by the LoadBalancer in your DNS server.
|
||||
- distinct: false
|
||||
+ distinct: true
|
||||
servicePort: 19092
|
||||
firstListenerPort: 31090
|
||||
- domain: cluster.local
|
||||
+ domain: example.com
|
||||
loadBalancerIP: []
|
||||
init:
|
||||
image: "lwolf/kubectl_deployer"
|
||||
@@ -173,11 +173,11 @@ configurationOverrides:
|
||||
# "advertised.listeners": |-
|
||||
# EXTERNAL://kafka.cluster.local:$((31090 + ${KAFKA_BROKER_ID}))
|
||||
## If external service type is LoadBalancer and distinct is true:
|
||||
- # "advertised.listeners": |-
|
||||
- # EXTERNAL://kafka-$((${KAFKA_BROKER_ID})).cluster.local:19092
|
||||
+ "advertised.listeners": |-
|
||||
+ EXTERNAL://kafka-$((${KAFKA_BROKER_ID})).example.com:19092
|
||||
## Uncomment to define the EXTERNAL Listener protocol
|
||||
- # "listener.security.protocol.map": |-
|
||||
- # PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
|
||||
+ "listener.security.protocol.map": |-
|
||||
+ PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
|
||||
|
||||
$ kubectl -n kafka get svc
|
||||
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
kafka ClusterIP 10.39.241.217 <none> 9092/TCP 2m39s
|
||||
kafka-0-external LoadBalancer 10.39.242.45 35.200.238.174 19092:30108/TCP 2m39s
|
||||
kafka-1-external LoadBalancer 10.39.241.90 35.244.44.162 19092:30582/TCP 2m39s
|
||||
kafka-2-external LoadBalancer 10.39.243.160 35.200.149.80 19092:30539/TCP 2m39s
|
||||
kafka-headless ClusterIP None <none> 9092/TCP 2m39s
|
||||
kafka-zookeeper ClusterIP 10.39.249.70 <none> 2181/TCP 2m39s
|
||||
kafka-zookeeper-headless ClusterIP None <none> 2181/TCP,3888/TCP,2888/TCP 2m39s
|
||||
|
||||
DNS A record entries:
|
||||
kafka-0.example.com A record 35.200.238.174 TTL 60sec
|
||||
kafka-1.example.com A record 35.244.44.162 TTL 60sec
|
||||
kafka-2.example.com A record 35.200.149.80 TTL 60sec
|
||||
|
||||
$ ping kafka-0.example.com
|
||||
PING kafka-0.example.com (35.200.238.174): 56 data bytes
|
||||
|
||||
$ kafkacat -b kafka-0.example.com:19092 -L
|
||||
Metadata for all topics (from broker 0: kafka-0.example.com:19092/0):
|
||||
3 brokers:
|
||||
broker 2 at kafka-2.example.com:19092
|
||||
broker 1 at kafka-1.example.com:19092
|
||||
broker 0 at kafka-0.example.com:19092
|
||||
0 topics:
|
||||
|
||||
$ kafkacat -b kafka-0.example.com:19092 -P -t gkeTest -p 0
|
||||
msg02 for topic gkeTest
|
||||
|
||||
$ kafkacat -b kafka-0.example.com:19092 -C -t gkeTest -p 0
|
||||
msg02 for topic gkeTest
|
||||
```
|
||||
|
||||
#### Example values.yml and DNS setup for external service type LoadBalancer with external.distinct: false
|
||||
The + lines are with the updated values.
|
||||
```
|
||||
external:
|
||||
- enabled: false
|
||||
+ enabled: true
|
||||
# type can be either NodePort or LoadBalancer
|
||||
- type: NodePort
|
||||
+ type: LoadBalancer
|
||||
# annotations:
|
||||
# service.beta.kubernetes.io/openstack-internal-load-balancer: "true"
|
||||
dns:
|
||||
@@ -138,10 +138,10 @@ external:
|
||||
distinct: false
|
||||
servicePort: 19092
|
||||
firstListenerPort: 31090
|
||||
domain: cluster.local
|
||||
loadBalancerIP: [35.200.238.174,35.244.44.162,35.200.149.80]
|
||||
init:
|
||||
image: "lwolf/kubectl_deployer"
|
||||
@@ -173,11 +173,11 @@ configurationOverrides:
|
||||
# "advertised.listeners": |-
|
||||
# EXTERNAL://kafka.cluster.local:$((31090 + ${KAFKA_BROKER_ID}))
|
||||
## If external service type is LoadBalancer and distinct is true:
|
||||
- # "advertised.listeners": |-
|
||||
- # EXTERNAL://kafka-$((${KAFKA_BROKER_ID})).cluster.local:19092
|
||||
+ "advertised.listeners": |-
|
||||
+ EXTERNAL://${LOAD_BALANCER_IP}:31090
|
||||
## Uncomment to define the EXTERNAL Listener protocol
|
||||
- # "listener.security.protocol.map": |-
|
||||
- # PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
|
||||
+ "listener.security.protocol.map": |-
|
||||
+ PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
|
||||
|
||||
$ kubectl -n kafka get svc
|
||||
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
kafka ClusterIP 10.39.241.217 <none> 9092/TCP 2m39s
|
||||
kafka-0-external LoadBalancer 10.39.242.45 35.200.238.174 31090:30108/TCP 2m39s
|
||||
kafka-1-external LoadBalancer 10.39.241.90 35.244.44.162 31090:30582/TCP 2m39s
|
||||
kafka-2-external LoadBalancer 10.39.243.160 35.200.149.80 31090:30539/TCP 2m39s
|
||||
kafka-headless ClusterIP None <none> 9092/TCP 2m39s
|
||||
kafka-zookeeper ClusterIP 10.39.249.70 <none> 2181/TCP 2m39s
|
||||
kafka-zookeeper-headless ClusterIP None <none> 2181/TCP,3888/TCP,2888/TCP 2m39s
|
||||
|
||||
$ kafkacat -b 35.200.238.174:31090 -L
|
||||
Metadata for all topics (from broker 0: 35.200.238.174:31090/0):
|
||||
3 brokers:
|
||||
broker 2 at 35.200.149.80:31090
|
||||
broker 1 at 35.244.44.162:31090
|
||||
broker 0 at 35.200.238.174:31090
|
||||
0 topics:
|
||||
|
||||
$ kafkacat -b 35.200.238.174:31090 -P -t gkeTest -p 0
|
||||
msg02 for topic gkeTest
|
||||
|
||||
$ kafkacat -b 35.200.238.174:31090 -C -t gkeTest -p 0
|
||||
msg02 for topic gkeTest
|
||||
```
|
||||
|
||||
## Known Limitations
|
||||
|
||||
* Only supports storage options that have backends for persistent volume claims (tested mostly on AWS)
|
||||
* KAFKA_PORT will be created as an envvar and brokers will fail to start when there is a service named `kafka` in the same namespace. We work around this be unsetting that envvar `unset KAFKA_PORT`.
|
||||
|
||||
[brokerconfigs]: https://kafka.apache.org/documentation/#brokerconfigs
|
||||
|
||||
## Prometheus Stats
|
||||
|
||||
### Prometheus vs Prometheus Operator
|
||||
|
||||
Standard Prometheus is the default monitoring option for this chart. This chart also supports the CoreOS Prometheus Operator,
|
||||
which can provide additional functionality like automatically updating Prometheus and Alert Manager configuration. If you are
|
||||
interested in installing the Prometheus Operator please see the [CoreOS repository](https://github.com/coreos/prometheus-operator/tree/master/helm) for more information or
|
||||
read through the [CoreOS blog post introducing the Prometheus Operator](https://coreos.com/blog/the-prometheus-operator.html)
|
||||
|
||||
### JMX Exporter
|
||||
|
||||
The majority of Kafka statistics are provided via JMX and are exposed via the [Prometheus JMX Exporter](https://github.com/prometheus/jmx_exporter).
|
||||
|
||||
The JMX Exporter is a general purpose prometheus provider which is intended for use with any Java application. Because of this, it produces a number of statistics which
|
||||
may not be of interest. To help in reducing these statistics to their relevant components we have created a curated whitelist `whitelistObjectNames` for the JMX exporter.
|
||||
This whitelist may be modified or removed via the values configuration.
|
||||
|
||||
To accommodate compatibility with the Prometheus metrics, this chart performs transformations of raw JMX metrics. For example, broker names and topics names are incorporated
|
||||
into the metric name instead of becoming a label. If you are curious to learn more about any default transformations to the chart metrics, please have reference the [configmap template](https://github.com/kubernetes/charts/blob/master/incubator/kafka/templates/jmx-configmap.yaml).
|
||||
|
||||
### Kafka Exporter
|
||||
|
||||
The [Kafka Exporter](https://github.com/danielqsj/kafka_exporter) is a complementary metrics exporter to the JMX Exporter. The Kafka Exporter provides additional statistics on Kafka Consumer Groups.
|
||||
|
|
@ -1,21 +0,0 @@
|
|||
# Patterns to ignore when building packages.
|
||||
# This supports shell glob matching, relative path matching, and
|
||||
# negation (prefixed with !). Only one pattern per line.
|
||||
.DS_Store
|
||||
# Common VCS dirs
|
||||
.git/
|
||||
.gitignore
|
||||
.bzr/
|
||||
.bzrignore
|
||||
.hg/
|
||||
.hgignore
|
||||
.svn/
|
||||
# Common backup files
|
||||
*.swp
|
||||
*.bak
|
||||
*.tmp
|
||||
*~
|
||||
# Various IDEs
|
||||
.project
|
||||
.idea/
|
||||
*.tmproj
|
||||
|
|
@ -1,17 +0,0 @@
|
|||
apiVersion: v1
|
||||
appVersion: 3.5.5
|
||||
description: Centralized service for maintaining configuration information, naming,
|
||||
providing distributed synchronization, and providing group services.
|
||||
home: https://zookeeper.apache.org/
|
||||
icon: https://zookeeper.apache.org/images/zookeeper_small.gif
|
||||
kubeVersion: ^1.10.0-0
|
||||
maintainers:
|
||||
- email: lachlan.evenson@microsoft.com
|
||||
name: lachie83
|
||||
- email: owensk@google.com
|
||||
name: kow3ns
|
||||
name: zookeeper
|
||||
sources:
|
||||
- https://github.com/apache/zookeeper
|
||||
- https://github.com/kubernetes/contrib/tree/master/statefulsets/zookeeper
|
||||
version: 2.1.0
|
||||
|
|
@ -1,6 +0,0 @@
|
|||
approvers:
|
||||
- lachie83
|
||||
- kow3ns
|
||||
reviewers:
|
||||
- lachie83
|
||||
- kow3ns
|
||||
|
|
@ -1,145 +0,0 @@
|
|||
# incubator/zookeeper
|
||||
|
||||
This helm chart provides an implementation of the ZooKeeper [StatefulSet](http://kubernetes.io/docs/concepts/abstractions/controllers/statefulsets/) found in Kubernetes Contrib [Zookeeper StatefulSet](https://github.com/kubernetes/contrib/tree/master/statefulsets/zookeeper).
|
||||
|
||||
## Prerequisites
|
||||
* Kubernetes 1.10+
|
||||
* PersistentVolume support on the underlying infrastructure
|
||||
* A dynamic provisioner for the PersistentVolumes
|
||||
* A familiarity with [Apache ZooKeeper 3.5.x](https://zookeeper.apache.org/doc/r3.5.5/)
|
||||
|
||||
## Chart Components
|
||||
This chart will do the following:
|
||||
|
||||
* Create a fixed size ZooKeeper ensemble using a [StatefulSet](http://kubernetes.io/docs/concepts/abstractions/controllers/statefulsets/).
|
||||
* Create a [PodDisruptionBudget](https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-disruption-budget/) so kubectl drain will respect the Quorum size of the ensemble.
|
||||
* Create a [Headless Service](https://kubernetes.io/docs/concepts/services-networking/service/) to control the domain of the ZooKeeper ensemble.
|
||||
* Create a Service configured to connect to the available ZooKeeper instance on the configured client port.
|
||||
* Optionally apply a [Pod Anti-Affinity](https://kubernetes.io/docs/concepts/configuration/assign-pod-node/#inter-pod-affinity-and-anti-affinity-beta-feature) to spread the ZooKeeper ensemble across nodes.
|
||||
* Optionally start JMX Exporter and Zookeeper Exporter containers inside Zookeeper pods.
|
||||
* Optionally create a job which creates Zookeeper chroots (e.g. `/kafka1`).
|
||||
* Optionally create a Prometheus ServiceMonitor for each enabled exporter container
|
||||
|
||||
## Installing the Chart
|
||||
You can install the chart with the release name `zookeeper` as below.
|
||||
|
||||
```console
|
||||
$ helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator
|
||||
$ helm install --name zookeeper incubator/zookeeper
|
||||
```
|
||||
|
||||
If you do not specify a name, helm will select a name for you.
|
||||
|
||||
### Installed Components
|
||||
You can use `kubectl get` to view all of the installed components.
|
||||
|
||||
```console{%raw}
|
||||
$ kubectl get all -l app=zookeeper
|
||||
NAME: zookeeper
|
||||
LAST DEPLOYED: Wed Apr 11 17:09:48 2018
|
||||
NAMESPACE: default
|
||||
STATUS: DEPLOYED
|
||||
|
||||
RESOURCES:
|
||||
==> v1beta1/PodDisruptionBudget
|
||||
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
|
||||
zookeeper N/A 1 1 2m
|
||||
|
||||
==> v1/Service
|
||||
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
zookeeper-headless ClusterIP None <none> 2181/TCP,3888/TCP,2888/TCP 2m
|
||||
zookeeper ClusterIP 10.98.179.165 <none> 2181/TCP 2m
|
||||
|
||||
==> v1beta1/StatefulSet
|
||||
NAME DESIRED CURRENT AGE
|
||||
zookeeper 3 3 2m
|
||||
|
||||
==> monitoring.coreos.com/v1/ServiceMonitor
|
||||
NAME AGE
|
||||
zookeeper 2m
|
||||
zookeeper-exporter 2m
|
||||
```
|
||||
|
||||
1. `statefulsets/zookeeper` is the StatefulSet created by the chart.
|
||||
1. `po/zookeeper-<0|1|2>` are the Pods created by the StatefulSet. Each Pod has a single container running a ZooKeeper server.
|
||||
1. `svc/zookeeper-headless` is the Headless Service used to control the network domain of the ZooKeeper ensemble.
|
||||
1. `svc/zookeeper` is a Service that can be used by clients to connect to an available ZooKeeper server.
|
||||
1. `servicemonitor/zookeeper` is a Prometheus ServiceMonitor which scrapes the jmx-exporter metrics endpoint
|
||||
1. `servicemonitor/zookeeper-exporter` is a Prometheus ServiceMonitor which scrapes the zookeeper-exporter metrics endpoint
|
||||
|
||||
## Configuration
|
||||
You can specify each parameter using the `--set key=value[,key=value]` argument to `helm install`.
|
||||
|
||||
Alternatively, a YAML file that specifies the values for the parameters can be provided while installing the chart. For example,
|
||||
|
||||
```console
|
||||
$ helm install --name my-release -f values.yaml incubator/zookeeper
|
||||
```
|
||||
|
||||
## Default Values
|
||||
|
||||
- You can find all user-configurable settings, their defaults and commentary about them in [values.yaml](values.yaml).
|
||||
|
||||
## Deep Dive
|
||||
|
||||
## Image Details
|
||||
The image used for this chart is based on Alpine 3.9.0.
|
||||
|
||||
## JVM Details
|
||||
The Java Virtual Machine used for this chart is the OpenJDK JVM 8u192 JRE (headless).
|
||||
|
||||
## ZooKeeper Details
|
||||
The chart defaults to ZooKeeper 3.5 (latest released version).
|
||||
|
||||
## Failover
|
||||
You can test failover by killing the leader. Insert a key:
|
||||
```console
|
||||
$ kubectl exec zookeeper-0 -- bin/zkCli.sh create /foo bar;
|
||||
$ kubectl exec zookeeper-2 -- bin/zkCli.sh get /foo;
|
||||
```
|
||||
|
||||
Watch existing members:
|
||||
```console
|
||||
$ kubectl run --attach bbox --image=busybox --restart=Never -- sh -c 'while true; do for i in 0 1 2; do echo zk-${i} $(echo stats | nc <pod-name>-${i}.<headless-service-name>:2181 | grep Mode); sleep 1; done; done';
|
||||
|
||||
zk-2 Mode: follower
|
||||
zk-0 Mode: follower
|
||||
zk-1 Mode: leader
|
||||
zk-2 Mode: follower
|
||||
```
|
||||
|
||||
Delete Pods and wait for the StatefulSet controller to bring them back up:
|
||||
```console
|
||||
$ kubectl delete po -l app=zookeeper
|
||||
$ kubectl get po --watch-only
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
zookeeper-0 0/1 Running 0 35s
|
||||
zookeeper-0 1/1 Running 0 50s
|
||||
zookeeper-1 0/1 Pending 0 0s
|
||||
zookeeper-1 0/1 Pending 0 0s
|
||||
zookeeper-1 0/1 ContainerCreating 0 0s
|
||||
zookeeper-1 0/1 Running 0 19s
|
||||
zookeeper-1 1/1 Running 0 40s
|
||||
zookeeper-2 0/1 Pending 0 0s
|
||||
zookeeper-2 0/1 Pending 0 0s
|
||||
zookeeper-2 0/1 ContainerCreating 0 0s
|
||||
zookeeper-2 0/1 Running 0 19s
|
||||
zookeeper-2 1/1 Running 0 41s
|
||||
```
|
||||
|
||||
Check the previously inserted key:
|
||||
```console
|
||||
$ kubectl exec zookeeper-1 -- bin/zkCli.sh get /foo
|
||||
ionid = 0x354887858e80035, negotiated timeout = 30000
|
||||
|
||||
WATCHER::
|
||||
|
||||
WatchedEvent state:SyncConnected type:None path:null
|
||||
bar
|
||||
```
|
||||
|
||||
## Scaling
|
||||
ZooKeeper can not be safely scaled in versions prior to 3.5.x
|
||||
|
||||
## Limitations
|
||||
* Only supports storage options that have backends for persistent volume claims.
|
||||
|
|
@ -1,7 +0,0 @@
|
|||
Thank you for installing ZooKeeper on your Kubernetes cluster. More information
|
||||
about ZooKeeper can be found at https://zookeeper.apache.org/doc/current/
|
||||
|
||||
Your connection string should look like:
|
||||
{{ template "zookeeper.fullname" . }}-0.{{ template "zookeeper.fullname" . }}-headless:{{ .Values.service.ports.client.port }},{{ template "zookeeper.fullname" . }}-1.{{ template "zookeeper.fullname" . }}-headless:{{ .Values.service.ports.client.port }},...
|
||||
|
||||
You can also use the client service {{ template "zookeeper.fullname" . }}:{{ .Values.service.ports.client.port }} to connect to an available ZooKeeper server.
|
||||
|
|
@ -1,46 +0,0 @@
|
|||
{{/* vim: set filetype=mustache: */}}
|
||||
{{/*
|
||||
Expand the name of the chart.
|
||||
*/}}
|
||||
{{- define "zookeeper.name" -}}
|
||||
{{- default .Chart.Name .Values.nameOverride | trunc 63 | trimSuffix "-" -}}
|
||||
{{- end -}}
|
||||
|
||||
{{/*
|
||||
Create a default fully qualified app name.
|
||||
We truncate at 63 chars because some Kubernetes name fields are limited to this (by the DNS naming spec).
|
||||
If release name contains chart name it will be used as a full name.
|
||||
*/}}
|
||||
{{- define "zookeeper.fullname" -}}
|
||||
{{- if .Values.fullnameOverride -}}
|
||||
{{- .Values.fullnameOverride | trunc 63 | trimSuffix "-" -}}
|
||||
{{- else -}}
|
||||
{{- $name := default .Chart.Name .Values.nameOverride -}}
|
||||
{{- if contains $name .Release.Name -}}
|
||||
{{- .Release.Name | trunc 63 | trimSuffix "-" -}}
|
||||
{{- else -}}
|
||||
{{- printf "%s-%s" .Release.Name $name | trunc 63 | trimSuffix "-" -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
|
||||
{{/*
|
||||
Create chart name and version as used by the chart label.
|
||||
*/}}
|
||||
{{- define "zookeeper.chart" -}}
|
||||
{{- printf "%s-%s" .Chart.Name .Chart.Version | replace "+" "_" | trunc 63 | trimSuffix "-" -}}
|
||||
{{- end -}}
|
||||
|
||||
{{/*
|
||||
The name of the zookeeper headless service.
|
||||
*/}}
|
||||
{{- define "zookeeper.headless" -}}
|
||||
{{- printf "%s-headless" (include "zookeeper.fullname" .) | trunc 63 | trimSuffix "-" -}}
|
||||
{{- end -}}
|
||||
|
||||
{{/*
|
||||
The name of the zookeeper chroots job.
|
||||
*/}}
|
||||
{{- define "zookeeper.chroots" -}}
|
||||
{{- printf "%s-chroots" (include "zookeeper.fullname" .) | trunc 63 | trimSuffix "-" -}}
|
||||
{{- end -}}
|
||||
|
|
@ -1,20 +0,0 @@
|
|||
{{- if .Values.exporters.jmx.enabled }}
|
||||
apiVersion: v1
|
||||
kind: ConfigMap
|
||||
metadata:
|
||||
name: {{ .Release.Name }}-jmx-exporter
|
||||
namespace: {{ .Release.Namespace }}
|
||||
labels:
|
||||
app: {{ template "zookeeper.name" . }}
|
||||
chart: {{ template "zookeeper.chart" . }}
|
||||
release: {{ .Release.Name }}
|
||||
heritage: {{ .Release.Service }}
|
||||
data:
|
||||
config.yml: |-
|
||||
hostPort: 127.0.0.1:{{ .Values.env.JMXPORT }}
|
||||
lowercaseOutputName: {{ .Values.exporters.jmx.config.lowercaseOutputName }}
|
||||
rules:
|
||||
{{ .Values.exporters.jmx.config.rules | toYaml | indent 6 }}
|
||||
ssl: false
|
||||
startDelaySeconds: {{ .Values.exporters.jmx.config.startDelaySeconds }}
|
||||
{{- end }}
|
||||
Some files were not shown because too many files have changed in this diff Show more
Loading…
Add table
Reference in a new issue